Backtrace 是怎么产生的
backtrace 的实现依赖于栈指针(fp寄存器),FP寄存器保存的是上一个函数的栈底,然后一层层出栈即可得到函数调用过程。在gcc编译过程中任何非零的优化等级(-On参数)或加入了栈指针优化参数 -fomit-frame-pointer 后多将不能正确得到程序栈信息。
CAS 是什么东西
CAS(Compare And Swap) 是一种无锁实现原子性数据更新的操作。具体而言,CAS 机制中有三个核心参数:V,A,B。其中,V 是数据对应的内存地址,A 是 V 地址对应的数据旧的期望值,B 是数据新的期望值。当线程要通过 CAS 机制修改主内存 V 中的值,则先将旧的数据期望值 A 读出到工作内存,在将新的期望值 B 写入到主内存前,先比较当前内存 V 中的数据是否等于 A,如果是,证明该内存处存储的数据没有被修改过,将 B 写入,并返回 true;否则,不作任何操作并返回 false。
CAS 的全过程在操作系统中只由一条不可分割的 cmpxchgl 硬件汇编指令实现,指令执行不可中断,是直接对 CPU 进行操作,从而在硬件层面保证了其原子性。但是,单单这一条指令在多核状态下依旧不能保证原子性。多和状态下需要在该指令前添加一条 lock 指令,该指令会锁定总线(阻止CPU通过总线读写内存,代价过高,当数据位于 L1~L3 Cache,且数据长度不超过 cache line ,则只会锁住缓存行)或 CPU 的缓存行从而保证操作的原子性。
进一步地,如果发现数据已经被其他线程更改,就开始轮询,不断重试,直到成功修改。就是 乐观锁 的一种实现。
CAS 的优缺点:
优点:
- 保证变量操作的原子性。
- 并发量不是很高的情况下,使用 CAS 机制比使用锁机制效率更高。
- 在线程对共享资源占用时间较短的情况下,使用 CAS 机制效率更高。
缺点:
-
ABA 问题:假设两个线程,线程1 和线程2, 按照顺序有如下操作:
1) 线程1 读取内存中的数据为 A;
2) 线程2 修改内存中的数据为 B;
3) 线程2 修改内存中的数据为 A;
4) 线程1 堆内存中的数据执行 CAS 操作。
显然,内存中的数据被线程2 修改过,但是线程1 在修改前比较读出时和当前的值相等, CAS 是可以成功的。
该问题带来的典型隐患如 栈顶问题 ,一个栈的栈顶经过两次(或多次)变化又恢复了原值,但是栈可能已发生了变化。解决 ABA 问题比较有效的方案是引入版本号,内存中的值每一次发生变化,版本号都 +1, 进行 CAS 操作时不仅比较内存中的值,也比较版本号是否相等,只有当二者都未变化时,CAS 才能成功执行。
-
高竞争下的开销问题。实际这属于使用 CAS 实现的乐观锁的问题,在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大。针对这个问题的一个思路是引入退出机制,如重试次数超过一定阈值后失败退出。当然,更重要的是避免在高竞争环境下使用乐观锁。
-
CAS 只能保证变量操作的原子性,无法保证整个代码块的线程安全。
什么是原子性
上文提到了原子性。原子性是指一个或者多个操作在 CPU 执行的过程中不被中断的特性,要么完整执行成功,要么退回到初始状态,,不能只执行到一半。
乐观锁,悲观锁,互斥锁,自旋锁,读写锁是些什么锁
-
乐观锁:
乐观锁或悲观锁是一种编程思想,并不是真正的实现。乐观锁实际上是不加锁,是一种无锁编程方式。乐观锁认为,其他线程争抢共享变量的概率相对小,所以更新数据的时候不会对共享变量加锁,但是在正式将数据写入内存之前会检查该数据是否被其他线程修改过(值或版本号)。如果未被修改过,则写入内存完成修改,否则就重试直到成功为止。可以认为,CAS + 轮询 就是乐观锁的一种实现。乐观锁适用于冲突概率较低的情况,适用于读操作较多的应用类型,这样可以提高吞吐量。
一个典型的例子是在线文档,由于发生冲突的概率较低,所以先允许用户进行编辑,但是浏览器下载文档时会记录下服务端返回的文档版本号;当用户提交修改时,发送给服务端的请求会带上原始文档的版本号,服务器收到后将它与当前版本号进行比较。版本号一致则修改成功,否则修改失败。 -
悲观锁:
悲观锁则认为目标资源被其他线程竞争的概率相对较大,因此操作共享资源的时候总是对资源加锁,直到操作结束后释放。加锁的资源既可以是变量,也可以是代码块。互斥所、自旋锁和读写锁等等都是悲观锁的具体实现。 -
互斥锁:
互斥锁和自旋锁是最基本的两种加锁方式,是其他较高级锁的基础。当已经有一个线程加锁后,其他线程加锁则就会失败,互斥锁和自旋锁的区别就在于对于加锁失败的线程的处理方式上。
互斥锁加锁失败后,当前线程会 释放 CPU 资源 给其他线程,自己进入阻塞状态,从用户态陷入到内核态。当锁被释放后,内核负责将该线程重新唤醒,由阻塞状态恢复为就绪状态,从内核态恢复到用户态。
互斥所存在一定的性能开销成本。具体而言,线程互斥锁加锁失败后存在从用户态(就绪)到内核态(阻塞)和从内核态返回用户态的两次转换,相应地需要保存和恢复线程相关的寄存器和栈,也就是线程的上下文切换。于是如果被锁住的代码的执行时间较短,甚至比线程上下文切换的时间还短,就不应该使用互斥锁。 -
自旋锁:
自旋锁则不存在线程上线文切换的问题。一般的,加锁过程分为两步:查看锁的状态,如果空闲则将锁设为当前线程持有。自旋锁通过 CAS 函数实现这一过程。CAS 将这两部操作合并为一条不可分的硬件指令,在硬件层面保证了加锁操作的原子性。
使用自旋锁的时候,如果发生多线程竞争锁的情况,加锁失败的线程会进入 “忙等待” 状态,一直自旋,利用 CPU 周期,直到锁可用。忙等待可以通过 while 循环实现,但是用 CPU 级别的 PAUSE 指令更加节能。
自旋锁的系统开销较小,在多核系统中一般不主动产生线程上下文切换。但如果被锁住的代码执行时间较长,自旋状态的线程也会长时间占用 CPU 资源。与互斥锁正相反,自旋锁适用于代码执行时间较短的场景。
特别的,在单核单线程系统中,自旋锁是不适用的,即使代码里实现了自旋锁,其也会被编译器优化掉。这是因为当一个线程进入自旋状态,证明其正在等待某一资源。在单核单线程 CPU 系统中,一旦发生了这种自旋锁,那么当前持有资源的线程也会由于无法获得 CPU 而一直等待。这样,占用 CPU 的线程等待另一个线程释放资源,占用资源的线程等待另一个线程释放 CPU ,从而导致程序进入死锁。 -
读写锁:
互斥锁和共享锁是两种最基本的加锁方式,更高级的锁会选择其中一个进行升级,比如读写锁既可以选择互斥锁实现,也可以基于自旋锁实现。读写锁从字面意思我们也可以知道,它由 读锁 和 写锁 两部分构成,如果只读取共享资源用 读锁 加锁,如果要修改共享资源则用 写锁 加锁。
所以,读写锁适用于能明确区分读操作和写操作的场景。
读写锁的工作原理是:- 当 写锁 没有被线程持有,多个线程可以并发地持有 读锁 ,这大大提高了共享资源的访问效率。
- 当 写锁 被线程持有,读线程获取 读锁 的操作会被阻塞,其他线程获取 写锁 的操作也会被阻塞。
从而得出,写锁 是独占锁,任何时候只能被一个线程持有,可以有互斥锁或自旋锁等实现;而 读锁 是共享锁,可以同时被多个线程持有。
显然,读写锁在读多写少的场景下更能发挥出优势。根据优先级的不同,读写锁可以实现为 读优先锁 和 写优先锁 。
读优先锁期望的是,读锁能被更多的线程持有,以便提高读线程的并发性,它的工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 仍然可以成功获取读锁,最后直到读线程 A 和 C 释放读锁后,写线程 B 才可以成功获取写锁。
写优先锁希望优先服务写线程,其工作方式是,当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 获取读锁时会失败,于是读线程 C 将被阻塞在获取读锁的操作,这样只要读线程 A 释放读锁后,写线程 B 就可以成功获取写锁。读优先锁对于读线程的并发性更好,但如果一直有读线程获取读锁,那么写线程永远无法获取写锁,就产生了写线程饥饿的现象。同理,写优先锁情况下,如果一直有写线程获取写锁,读线程也会产生饥饿现象。对于线程饥饿问题的一种解决方式是“读写公平锁”:
读写公平锁的一种简单实现是,维护一个队列,所有获取锁的线程按顺序入队列,不管是读线程还是写线程,按照先进先出的原则出队列加锁即可。这样读线程仍然可以并发,也不会出现饥饿现象。
Debug 和 Release
Debug 版本和 Release 版本其实就是 C/C++ 编译器优化级别的不同。gcc/g++ 编译器的有如下几种优化级别:
- O0: 默认级别,不开启优化项,方便调试,也就是 BEBUG 模式。
- Og: 开启部分不影响调试信息的优化项。
- O1: 较保守的优化。
- O2: 常见的 Release 级别,打开几乎全部优化项。
- Os: 比 O2 更保守一些。
- O3: 更加激进。
- Ofast: 不严格遵循标准,在 O3 的基础上开启一些可能导致不符合 IEEE 浮点数标准的优化项。
DEBUG 是调试版本,编译的结果通常包含调试信息,不进行任何优化,因此代码运行相对较慢。RELEASE 是发布版本,不携带调试信息,比如断点,同时编译器对代码进行很多优化,是代码更小,速度更快。RELEASE 因此也比 DEBUG 需要更长的编译时间。
DEBUG 模式下,申请内存时会多分配一些内存空间,分布在申请内存块的前后,用于存放调试信息;RELEASE 则不会。对于未初始化变量,DEBUG 默认将其初始化,RELEASE 则不会。DEBUG 下可以使用断言,RELEASE 则会直接无视掉断言语句。 DEBUG 以 32 字节为单位分配内存,例如当申请 24 字节内存时,RELEASE 是正常的 24 字节,而 DEBUG 则会多申请 8 个字节;所以有些数组越界问题在 DEBUG 模式下可以安全运行,RELEASE 模式下则会出现问题。DEBUG 模式下记录了可以正常使用 gdb 去 debug,但是 RELEASE 可能会将用于记录程序运行信息的符号表 优化掉,导致无法直接 gdb。如果需要在 release 版本 gdb 的话,可以使用 objcopy 生成一个 debug 信息,在 gdb 的时候,先加载符号信息 file xxx.debug,然后再进行调试。
Core Dump 是怎么产生的
上文提到了 core dump 。当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump。 使用命令 gdb program core 来查看 core 文件,其中 program 为可执行程序名,core 为生成的 core 文件名。
gcc/g++ ,cmake,和 make
上文提到了 gcc/g++ ,这里简述 linux 下常用于编译 c++ 项目的三者的关系。
gcc/g ++ 都是用于程序编译的程序,他们只调用编译器,本身并不是编译器。所不同的是面对不同后缀名文件时的动作。比如同样面对一个 后缀为 .c 的文件,g++ 认为是 c++ 程序,会调用 cc1plus 编译器进行编译,而 gcc 认为其是 C 程序,会调用 cc1 编译器进行编译。
当项目只有一两个程序的时候,尚可以手动执行 gcc/g++ 进行编译。但如果项目中包含很多源文件或库文件,使用 gcc/g++ 手动去编译则很容易混乱,且工作量较大。这种情况下可以使用 make 工具。
make 是一种智能批处理工具,它本身没有编译和连接功能,而是通过调用 Makefile 文件中用户指定的命令进行编译连接。但是 Makefile 文件的语法相当冗长啰嗦,项目较小的时候上可以手动编写或修改,当工程较大的时候,手写 Makefile 也成了一件麻烦事。而且 make 工具是平台相关的,在一个平台上编写好的 Makefile 一直到另一个平台上,就不能用了,需要重新编写。很麻烦。
cmake 工具可以解决这个问题。cmake 可以根据 CMakeLists.txt 文件自动生成 MakeFile,CMakeLists.txt 文件的语法相对简洁易懂,其基本使用见CMake 基本使用。且 cmake 跨平台,基于不同平台可以生成对应 MakeFile 文件。
库文件和头文件,静态库和动态库(共享库)
C/C++ 程序编译的时候需要连接头文件和库文件,简单介绍。
头文件。稍微大型的面向对象项目中,为了做到高内聚低耦合,项目代码通常被根据功能分成很多部分,而不是将所有代码写到一个源文件里。通常,函数或类的声明和具体实现是分开的,头文件中包含函数的声明,简洁易读,库文件中包含函数的具体实现,可读性较差但实现高效。库文件通过头文件向外暴露接口,编译时链接器就可以根据头文件中的信息找到函数的具体实现并链接到程序的代码段中。
库文件。库文件是函数具体实现的封装,通常以二进制而不是源码形式保存函数的具体实现,通过对应的头文件暴露接口。从而实现对具体实现保密的目的。通常,库文件分为静态库和动态库两种,在 linux 下前者后缀 .a,后者后缀 .so 。两者的区别在于载入的时刻不同,静态库在编译时就全部被装载进可执行程序中,动态库在编译时仅做引用,在运行时动态载入内存:
- 静态库在编译时就被编译进了可执行程序,生成可执行文件后删除库文件,程序仍可运行。
- 动态库被编译进可执行程序的只有函数接口,运行时仍然依赖于库。如果删除库文件,将导致程序无法运行。
- 静态库由于是静态嵌入,程序运行速度较快,但是程序体积较大,不易更新和维护,升级的话需要重新编译。
- 动态库由于是运行时动态加载,因此程序运行速度较慢,体积较小,升级程序不需要重新编译。
- 静态库的链接只需要将静态库文件添加到 g++ 后面即可,比如:
g++ main.cpp build/libtest.a -o helloworld对于引用关系稍微复杂一点的程序来说,静态库简直就是灾难,到处都是错误。
- 动态库的链接需要指明头文件的搜索路径(目录一级)和库文件的搜索路径(文件一级):
g++ -I /user/local/workflow/include -L /usr/local/workflow/libs/Workflow.so *.cpp -o main上面
-I选项就是指定头文件的搜索路径,精确到目录一级;-L项指明库文件路径,精确到具体文件一级。
但是, 当编译连接结束生成可执行文件后,在运行的时候会出现 “Workflow.so not found” 等错误,这是因为 g++ 在连接的时候搜索到了第三方库,但是运行的时候库文件不在程序的第三方库默认搜索路径中。所以需要添加-Wl, -rpath=具体目录参数将第三方库所在的目录加入到运行时搜索路径中:g++ -I /user/local/workflow/include -L /usr/local/workflow/libs/Workflow.so -Wl,-rpath=/usr/local/workflow/libs *.cpp -o main
软连接和硬连接
Linux 中的链接分两种,一种被称为硬连接(Hard Link),由 ln 指令产生,另一种被称为符号链接(Symbolic Link),也称为软连接,由 ln -s 指令产生。
硬链接
硬链接只通过索引节点来进行连接。在 Linux 文件系统中,保存在磁盘分区中的文件不管是什么类型都会给它分配一个编号,称为索引节点号(Inode Index)。Linux 允许多个文件名指向同一索引节点。当我们为文件 B 建立一个硬连接 A ,则 A 的目录项中的 inode 节点号与 B 的目录项中的 inode 节点号相同,即一个 inode 节点号对应两个不同的文件名,两个文件名指向同一个文件。当一个硬连接被建立(B -> A),硬连接和源文件对文件系统是平等的,删除其中任意一个都不会影响另一个对文件数据的访问。
硬链接允许一个文件拥有多个有效路径名,且当且仅当所有硬链接和源文件都被删除,文件的数据块及目录的连接才会被释放,。也就是说,文件真正删除的条件是文件本身及与之相关的所有硬连接都被删除。这样用户就可以建立硬连接到重要文件,防止误删文件。
软连接
符号链接又称为软连接。软连接文件类似于 windows 系统中的快捷方式,他是一个特殊的文件。符号连接中,文件实际上是一个文本文件,其中包含着另一个文件的位置信息。比如,A 是 B 的软连接,则 A 的目录相中的 inode 节点号和 B 的目录相中的 inode 节点号是不相同的,A 和 B 指向两个不同的 inode 继而指向凉快不同的数据块。从而,源文件 B 和软连接 A 对文件系统不是平等的,他们有“主从”关系。链接删除不影响源文件,源文件删除则会导致链接成为一个无效的死链接。
零拷贝
网络编程中,服务端面临客户端请求时,会发生如下系统调用:
// 伪代码
File::read(file, buf, len);
Socket::send(socket, bufm len);
也即将数据从外部存储设备读入用户空间,然后通过外部发送设备(网卡)发送出去。在没有使用任何优化技术的情况下,这一过程需要进行四次数据拷贝,进行四次上下文切换,如下图所示:
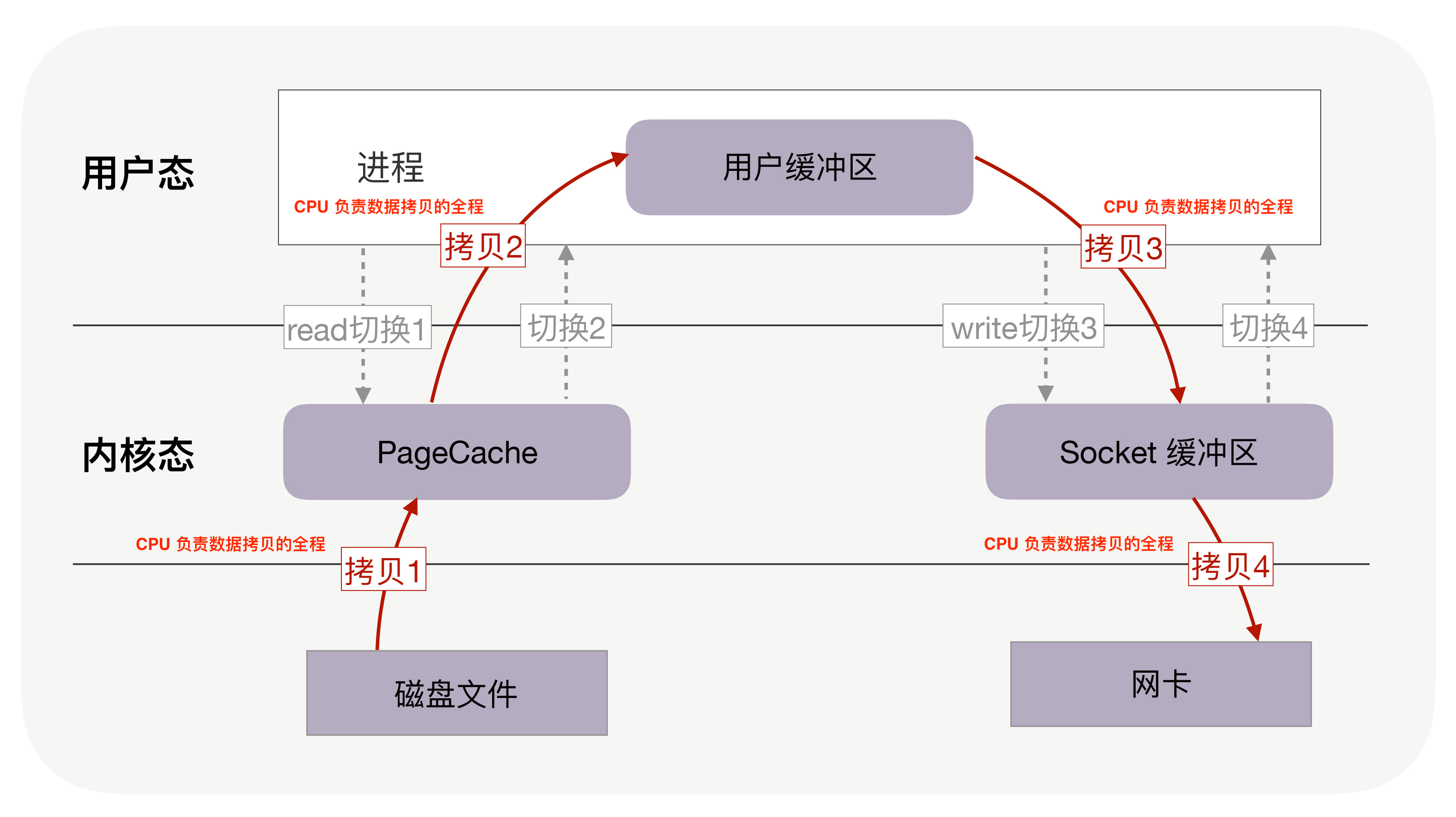
其中,四次拷贝:
- 物理设备 <–> 内存:
- CPU 负责将数据从硬盘拷贝到内核空间的 Page Cache 中。
- CPU 负责将数据从内核空间的 Socket 缓冲区拷贝到网络设备中。
- 内存内部拷贝:
- CPU 负责将数据从内核空间的 Page Cache 拷贝到用户控件缓冲区。
- CPU 负责将数据从用户空间缓冲区拷贝到内核空间 Socket 缓冲区。
线程的四次上下文切换:
- read 系统调用时,从用户态切换到内核态。
- read 系统调用完毕,从内核态切换回用户态。
- write 系统调用时,从用户态陷入到内核态。
- write 系统调用完毕,从内核态恢复到用户态。
CPU 直接控制硬盘数据 IO 需要 CPU 不断轮询当前字节数据 IO 是否完成,但由于 CPU 处理速度较高,而设备间 IO 速度较慢,这种方式往往导致 CPU 大多数时间处于忙等待状态,效率较低。上下文切换的成本也不小:一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
现代计算机通过 DMA (Direct Memory Access,直接内存访问) 机制实现设备间 IO,也即通过主板上的 DMAC (DMA Controller,DMA 控制器) 控制数据 IO。DMAC 作为一个协控制器接管线程负责设备间 IO,在此期间 CPU 资源被释放,并在 IO 完成后,通知 CPU 重新接管线程。但是设备内部的数据拷贝还需要 CPU 来亲力亲为。如下图:
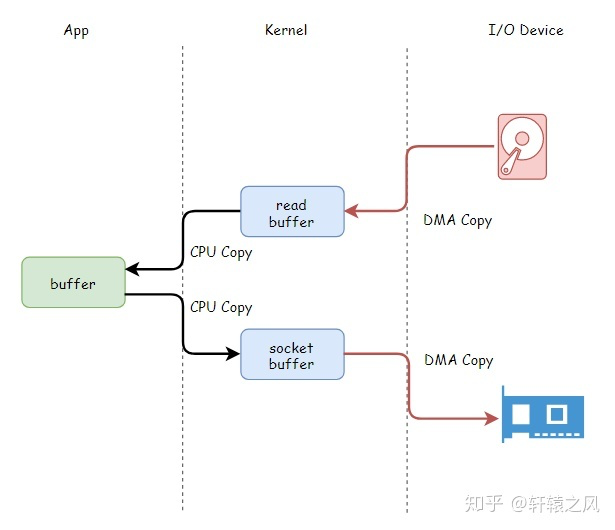
DMA 机制是实现零拷贝的的基础之一。零拷贝并不是没有拷贝数据,而是减少用户态/内核态的切换次数以及 CPU 负责拷贝的次数,主要是用来解决操作系统在处理 I/O 操作时,频繁复制数据的问题。关于零拷贝主要技术有 mmap+write、sendfile 和 splice 等几种方式。
mmap + write
mmap 依据虚拟内存空间而实现。现代操作系统中,进程(用户态和内核态)无法直接访问真实的物理内存地址,进程能看到的所有地址组成的空间,实际是虚拟内存空间。而虚拟内存空间和物理内存空间存在映射关系,进程通过虚拟内存和虚拟内存与物理内存之间的映射关系间接访问物理内存。是用虚拟内存空间有两种好处:
- 虚拟内存空间可以远大于物理内存空间
- 多个虚拟内存地址可以指向同一个物理地址
mmap 正是基于后者而实现。它将用户空间和内核空间的虚拟地址映射到同一个物理地址,从而在读数据的时候,只需要 DMA 将磁盘数据拷贝到内核空间即可,而不需要继续从内核空间拷贝到用户空间。通过将用户空间的缓冲区映射到和内核读空间缓冲区相同的物理地址,再次向外部设备写入数据的时候,则直接在内核空间,由内核读缓冲区拷贝到 socket 缓冲区。其具体流程如下:
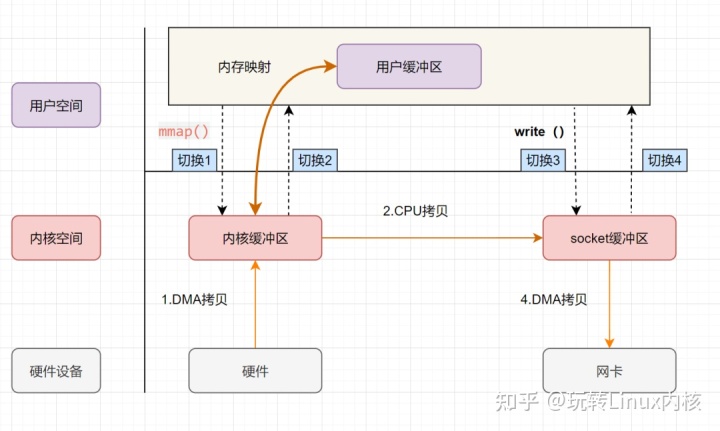
- 用户进程通过 mmap 方法箱操作系统内核发起 IO 调用,上下文从用户态切换到内核态。
- CPU 通过 DMAC 将数据从存储设备拷贝到内核缓冲区。
- IO 完成,mmap 方法返回,上下文从内核态切换回用户态。
- 用户进程通过 write 方法箱操作系统内核发起 IO 调用,上下文从用户态切换到内核态。
- CPU 将内核读缓冲区内的数据拷贝到 socket 缓冲区。
- CPU 利用 DMAC 将数据从 socket 缓冲区拷贝到网卡。
- write 调用结束,上下文从内核态切换回用户态。
可以发现,mmap+write 方法实现的零拷贝,共发生了三次数据拷贝,包括 2 次设备间的 DMA 拷贝和一次内核空间中的 CPU 拷贝。但依然发生了四次用户空间和内核空间的上下文切换。
发现,从 mmap 调用结束,到发起 write 之间,数据跟本不经过用户空间,而上下文却仍需要切换回用户态再切回到内核态,产生了不小的性能浪费。那么,能不能省去这两次上下文切换,让上下文一直停留在内核空间,直到 write 结束再返回用户空间呢?方法就是 sendfile。
sendfile
sendfile 是 Linux2.1 内核引入的一个系统调用,API 为:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
sendfile 方法将文件描述符 in_fd 中,自 offset 位置(默认为 0 )开始的 count 长度的数据传输到文件描述符 out_fd 中。其返回值为传输的文件大小,传输成功则返回值与count相等。这个操作实现在操作系用内核中,避免了内核空间和用户空间的拷贝。同时,sendfile 将 read(); write(); 两次系统调用替换为了 sendfile() 一次系统调用,于是线程的上下文切换也就减少到了两次。其具体流程如下:
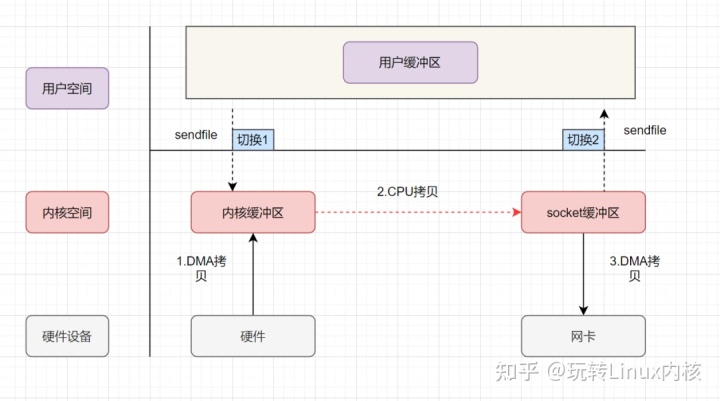
- 用户进程发起 sendfile 系统调用,上下文从用户态切换到内核态。
- CPU 通过 DMAC 将数据从外部设备拷贝到内核缓冲区。
- CPU 将内核读缓冲区的数据拷贝到 socket 缓冲区。
- CPU 通过 DMAC 将数据从 socket 缓冲区拷贝到网卡。
- sendfile 调用结束,上下文从内核态切换回用户态。
发现,sendfile 实现的零拷贝发生了三次数据拷贝和两次上下文切换。其中三次数据拷贝包括两次 DMA 和一次 CPU 拷贝。那么,能不能再进一步,不要 内核读缓冲区–> socket 缓冲区 这一步骤,将 CPU 拷贝的次数降低至 0 次,直接将数据从内核读缓冲区拷贝入网卡设备呢?可以的。
sendfile + DMA scatter/gather 实现的零拷贝
实际上,上述流程是原始的 sendfile ,在 Linux2.4 内核版本之后,引入了 SG-DMA 技术( 带 scatter/gather 的 DMA),对 sendfile 进行了升级。SG-DMA 技术可以直接从内核空间缓冲区中将数据读取到网卡。使用这个特点搞零拷贝,即还可以多省去一次CPU拷贝。其具体流程如下:
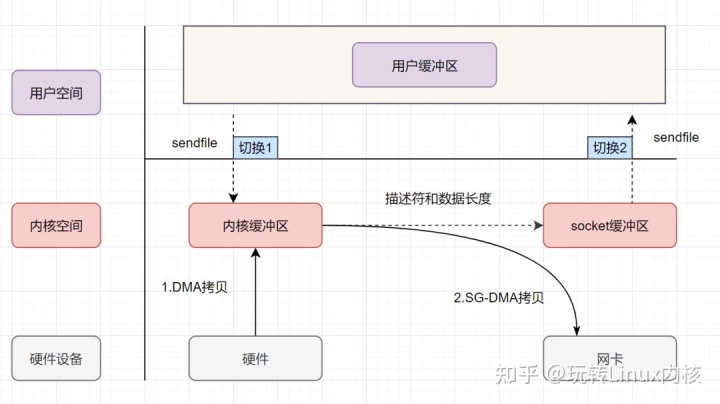
- 用户进程发起 sendfile 系统调用,上下文从用户态切换到内核态。
- CPU 通过 DMAC 将数据从外部存储设备拷贝到内核缓冲区。
- CPU 把内核缓冲区的文件描述符信息(包括内核缓冲区的内存地址和偏移量)发送到 socket 缓冲区。
- CPU 控制 DMAC,根据文件描述符信息,直接将数据从内核读缓冲区拷贝到网卡。
- sendfile 调用结束,上下文从内核态切换回用户态。
发现,sendfile + DMA scatter/gather 实现的零拷贝发生了两次上下文切换和两次设备间 DMA 拷贝,而 CPU 拷贝的次数为 0。这是真正的零拷贝技术,全程没有 CPU 负责的数据拷贝,所有数据都是通过 DMA 进行传输的。
!但是!: 基于 SG-DMA 技术实现的零拷贝,必须要网卡支持 scatter-gather 特性,否则依然是 普通 sendfile 机制。可以使用如下命令查看网卡的 scatter-gather 支持:
ethtool -k 网卡名 | grep scatter-gather
很可惜,我自己的机器的网卡并不支持 scatter-gather 。

零拷贝的缺陷
- 由于数据不经过用户空间,程序无法对数据进行修改。也就是说,零拷贝只适用于将数据不加处理地从硬盘发送到网卡的情况。
- 零拷贝依赖于 page cache 页面表。
Page Cache 是什么
上文提到了页缓存 Page Cache,作简要介绍。
由于读写硬盘的速度远远慢于读写内存的速度,所以我们应该尽量将 读磁盘 操作替换为 读内存 。但是,内存空间远比磁盘要小,内存注定只能拷贝磁盘里的一小部分数据。那应该选择哪些磁盘数据拷贝到内存呢?
程序运行的时候,具有 局部性 的特征 ,所以通常,刚被访问的数据在短时间内再次被访问的概率很高,于是我们可以用 PageCache 来缓存最近被访问的数据,当空间不足时淘汰最久未被访问的缓存。这样一来,发生数据读取系统调用的时候,程序优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。
Linux 内核会以页大小(4KB)为单位,将文件划分为多数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(页缓存)与文件中的数据块进行绑定。用户读写数据实际是对文件的 页缓存 进行读写:
- 当从文件中读取数据时,如果要读取的数据所在的页缓存已经存在,那么就直接把页缓存的数据拷贝给用户即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把页缓存的数据拷贝给用户。
- 当向文件中写入数据时,如果要写入的数据所在的页缓存已经存在,那么直接把新数据写入到页缓存即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把新数据写入到页缓存中。对于被修改的页缓存,内核会周期性地把这些页缓存刷新到文件中。
page cache 的回收机制
当物理内存空间紧张时,内核需要把已经缓存着的内容选择一部分清除。选择的策略通常是基于最近最少使用(LRU)而改进的 LRU/n 算法,也即维护 n 个最近最少使用链表,将最近被访问的页缓存插入链表尾,而链表头存储的就是最近最少使用的页缓存,可以被回收。
另一点是,读取磁盘数据的时候,需要找到数据所在的位置。对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再读取数据。但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了 预读功能 :假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低。如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
综上,PageCache 的优点主要是两个:
- 缓存最近被访问的数据;
- 预读功能;
这两个做法,大大提高了读写磁盘的性能。
大文件传输,直接 IO 和缓存 IO
上文提到了 page cache,page cache 技术在大多数情况下可以提升 IO 性能。但是在传输大文件的时候,文件整体或文件的某一部分再被访问到的概率很低,这个时候使用 page cache 不仅不再起作用,而且由于多做了一次拷贝,反而会造成性能降低。不止于此,除了大文件传输本身的性能降低之外,由于 pageCache 长期被大文件占据,高频率被访问的热点小文件就无法充分使用 page cache,这样读起来也变慢了。
所以,高并发场景下,为了防止 page cache 被大文件占满后不再对小文件起作用,大文件不应该使用 page cache ,进而也不应该使用零拷贝技术:应当使用异步 IO 和直接 IO 替换零拷贝技术。
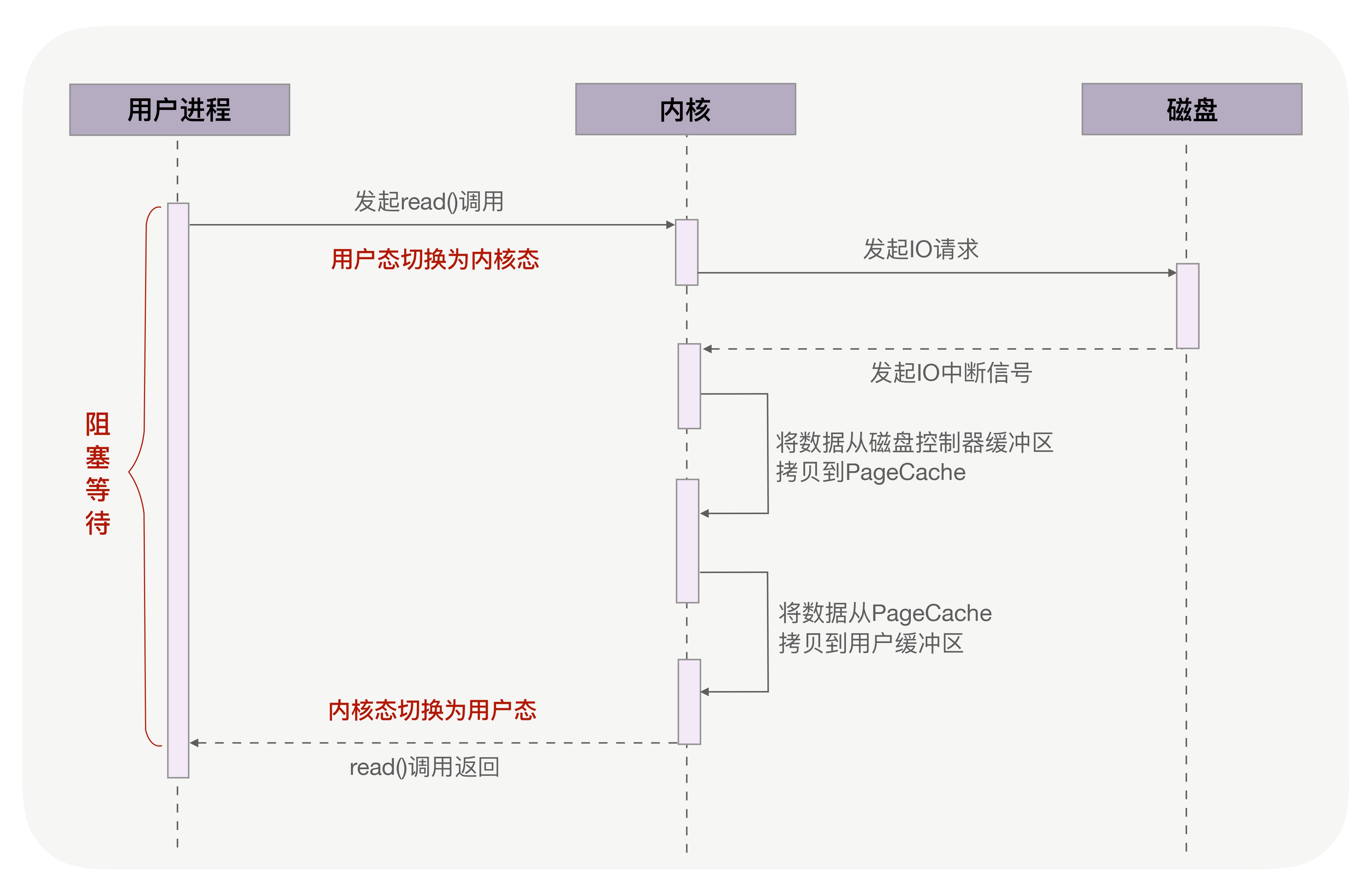
调用 read() 读取文件时,用户进程在磁盘寻址的过程中是阻塞等待的,阻塞直到数据读取完毕。这就导致进程无法并发地处理其他逻辑。这种请求进程阻塞(程序卡在 read() 语句)直到 IO 完成的是同步 IO。
而异步 IO 则不会阻塞进程,用户进程发起 IO 后不等待数据就位立刻返回,进程并发地处理其他非数据逻辑。当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据。
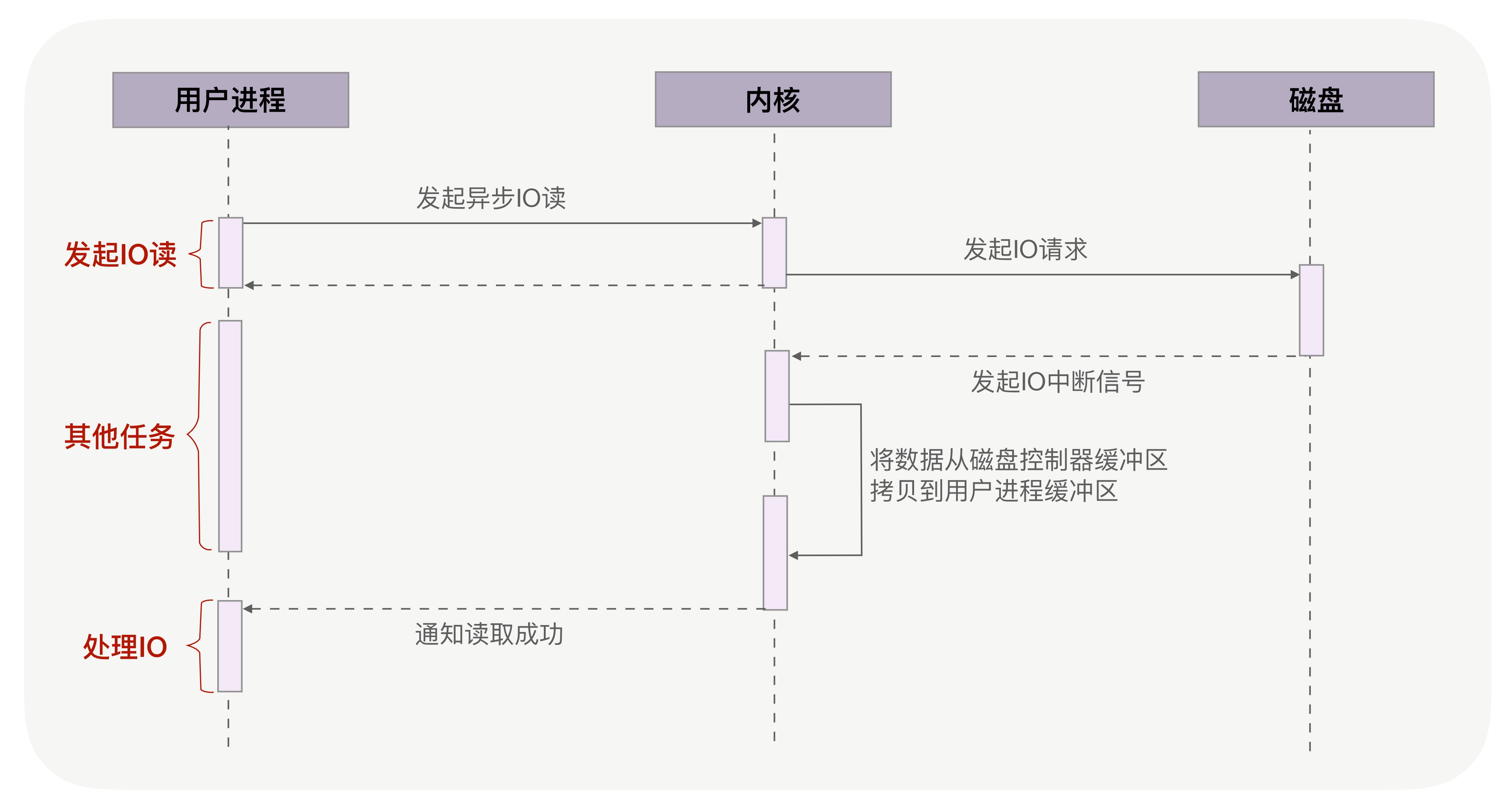
由于 page cache 机制和虚拟内存空间耦合太紧,异步 IO 数据从磁盘到用户空间的过程不经过 page cache,称为直接 IO;而经过 page cache 的 IO 称为缓存 IO。对于磁盘,异步 IO 只支持直接 IO。
服务端大文件传输由异步IO直接IO处理,小文件交由零拷贝处理,是一种更高效的 IO 策略,也是 Nginx 实际使用的的 IO 策略。至于什么是大文件什么是小文件,这个阈值则可以灵活设置。
IO 模型,阻塞和非阻塞,同步和异步
Linux 有五种 IO 模型:阻塞式 IO 模型,非阻塞 IO 模型,IO 复用模型,信号 IO 模型,异步 IO 模型,其中前四种都是同步 IO。
一般地,IO 操作可以分为两个阶段:等待数据就绪和数据拷贝到用户空间。等待数据就绪指的是数据从外部IO设备拷贝到内核缓冲区的过程,数据到达内核缓冲区成为就绪;后者就是字面意思,指数据从内核缓冲去拷贝到用户空间过程。阻塞和非阻塞这一区分发生在 第一阶段 ;同步和异步的区别体现在 第二阶段 。
- 阻塞IO/非阻塞IO
- 阻塞 IO 模型当用户进程发起 IO 系统调用,上下文陷入内核态,进程(线程)阻塞,释放 CPU 资源,直到 IO 结束、数据进入用户空间或 IO 超时才返回。
在一个进程只有一个套接字或只需要处理一个 IO 请求的时候,阻塞式 IO 还是相当划算的,因为在等待数据就绪的过程中进程是阻塞的,CPU 资源被释放用于处理其它进程。但如果一个进程负责多个 IO ,阻塞模型就不是一件好事了,因为线程阻塞导致无法并发地处理多个 IO,只能等待一个 IO 数据就绪再序列地处理下一个 IO。如果用多个线程每个线程负责一个 IO,则又会带来系统开销(上下文切换)过大和线程大部分时间空间等问题。
read(), accept(), send() 等系统调用或库函数,默认是阻塞的。 - 非阻塞 IO 模型当用户进程发起 IO 系统调用,上下文立刻返回。有数据则带回数据,没有数据则返回错误,标识资源不可用。
如果接收到错误,进程不会被阻塞,CPU 资源也不会被释放,进程会轮询数据是否就绪。在一个进程负责多个 IO 的场景下,非阻塞 IO 显然比阻塞 IO 更加高效,因为它可以并发地处理多个 IO ,并发地轮询多个 IO 的数据就绪状态。
但是如果并发量上去了,非阻塞模型也会力不从心,因为非阻塞模型监测不同 IO 事件的数据就绪状态采用的是轮询机制,基本等于盲猜。并发量一大,命中率就低了。
IO 多路复用模型可以解决高并发问题。
- 阻塞 IO 模型当用户进程发起 IO 系统调用,上下文陷入内核态,进程(线程)阻塞,释放 CPU 资源,直到 IO 结束、数据进入用户空间或 IO 超时才返回。
- 同步IO/异步IO
阻塞 IO 和非阻塞 IO 都是同步 IO 。同步和异步,描述的是调用者是否要主动等待函数的返回。- 同步 IO 无论是阻塞 IO 还是非阻塞 IO,在数据拷贝到用户空间这一过程,都是阻塞的。也就是需要用户进程主动发起请求,等待内核的返回。
同步 IO 适用于 IO 速度较快的场景,因为异步 IO 会使用回调函数接收内核的通知,如果 IO 本身就很快,回调函数的耗时占比提高,整体效率反而不高。 - 异步 IO 全阶段无阻塞,做到了调用后不管,数据一步到位。用户进程发出 IO 系统调用后立刻返回执行其他逻辑,内核接管 IO。当数据就绪并已经完成从内核缓冲去拷贝到用户空间的工作后,内核会向用户进程发送一个通知,用户进程此时可以继续处理数据相关逻辑。
异步 IO 适用于高并发场景(不一定是最优方案),但是需要系统支持。目前 Windows 实现的 IOCP 被认为是真正的异步,Linux 系统有两套 AIO,一个是 c++ 标准库里的 POSIX AIO(glibc_aio),一个是 Linux2.6 内核后实现的 libaio 。前者通过多线程模拟,后者目前只支持直接 IO。
特别的,异步 IO 也可以配合阻塞式IO ,但一般没有意义。
- 同步 IO 无论是阻塞 IO 还是非阻塞 IO,在数据拷贝到用户空间这一过程,都是阻塞的。也就是需要用户进程主动发起请求,等待内核的返回。
同步和异步
不局限于 IO 模型,同步和异步在程序逻辑上的最大差别是一个需要等待,一个不需要等待。
- 同步 就是发送一个请求,等待请求返回后才能继续发送下一个请求,程序存在严格的时序关系。适用于涉及共享资源写操作等对时序关系有需求的场景。
- 异步 是发送一个请求,不等待立刻返回执行其他逻辑,请求事件处理完毕后通过回调函数返回给用户进程结果,不存在时序关系。适用于如数据IO,共享资源读操作等对时序关系不存在较大需求的场景。
从阻塞式 IO 到 IO 多路复用
阻塞式 IO
在 socket 网络编程场景中,服务端处理客户端连接的最基本方式就是单线程阻塞式IO,伪代码如下:
listenfd = socket();
bind(listenfd);
listen(listenfd);
while(1){
connfd = accept(listenfd);
n = recv(connfd, buf);
doSomething(buf);
close(connfd);
}
代码所示的这个过程中,服务端线程阻塞主要发生在 accept 和 recv 两个部分,也就是建立连接和接收数据。对于网络 IO 来讲,我们主要关心 recv 接收数据这一部分。细究 read 函数的话,又可以分成前文所说的 IO 的两阶段:数据进入内核空间,数据拷贝到用户进程空间。这两个阶段无疑都是阻塞的。所以,如果当前建立连接的客户端一直不发数据,那么服务器线程就会一直阻塞在 recv 函数上不返回,自然没有办法接受其他客户端连接。
这肯定是不行的。
非阻塞式 IO
为了解决上面的问题,其关键在于改造 recv 函数(recv 和 read,在下一小节做简要介绍)。一种方法是,每次 accept 建立一个连接都为该链接创建一个新的线程,每个 IO 独占一个线程。伪代码如:
while(1){
connfd = accept(listenfd);
pthread_create(doWork);
}
void doWork(){
n = recv(connfd, buf);
doSomething(buf);
close(connfd);
}
这样,当一个连接建立好后,就可以立刻等待新的客户端连接,而不用阻塞在原客户端的 recv 请求上。然而,这种每个IO流独占一个线程的实现,是非常粗暴的,存在很多缺点:
- 在任何时刻,都可能有大量的线程处于空闲状态,造成资源浪费。
- 线程是占内存的,不太可能建立太多的工作线程。
- 线程的上限文切换也会带来不小的开销。
这并不是像真正的非阻塞,因为我们不过是使用多线程的手段使主线程没有卡在 recv 函数上,recv 这个系统调用踹然是阻塞的。要实现真正的非阻塞 IO,需要操作系统提供非阻塞的 recv 调用。
Linux 中,无论是 socket 还是本地读文件,默认都是阻塞的。Linux/C++ socket 编程中,在建立 socket 之后我们可以使用 fcntl() 或 ioctl() 给创建的 socket 增加 O_NONBLOCK 标识将 socket 设置为非阻塞模式:
int clientfd = socket(AF_INET, SOCK_STREAM, 0);
... ...
int oldSocketFlag = fcntl(clientfd, G_GETFL, 0);
int newSocketFlag = oldSocketFlag | O_NONBLOCK;
if (fcntl(clientfd, F_SETFL, newSocketFlag) == -1) {
close(clientfd);
perror("set error\n");
return -1;
}
此时接收 socket 数据就变成了非阻塞,也即 recv 立刻返回,有数据则带回数据,没有则带回错误。当错误码 errno == EWOULDBLOCK || errno == EAGAIN,代表错误数据未就绪,等待下一轮循环继续 recv;实际上,EWORLDBLOCK 和 EAGAIN 这两个错误码是一样的,值都是 11,没差别;如果是 errno == EINTR 代表着信号被中断,原因暂不细究,也是等待下一轮循环继续 recv。
Linux 下 socket 可以在创建套接字的时候给 type 增加一个标志位将其设置为非阻塞模式:
int s = socket(AF_INET, SOCK_STREAM | O_NONBLOCK, 0);
当然,对 open 打开,read 读取的本地文件,也可以在 open 的时候增加一个非阻塞标志位是文件变为非阻塞:
// int open(const char* pathname, int flag, mdoe_t mode);
int fd = open(filename, O_NONBLOCK, "w+");
此时,如果文件不能打开,则返回一个错误码,而不是阻塞 open()。当文件打开成功,后续的 IO 操作也是非阻塞的,也即 read/write 立即返回,有数据则带回数据,没有数据就带回错误。
具体怎么做才能并发的监测很多文件呢? 一个直接的实现是,每 accept 一个客户端,将这个文件描述符(connfd)放到一个数组里,然后用一个主线程轮询这个数据。也即非阻塞配合循环使用,就可以实现并发IO了:
while(true){
char buf[32] = {0};
int ret1 = recv(fd1, buf, sizeof(buf), 0);
if (ret1 < 0){
if (errno == EINTR)
perror("Interruption\n");
else if(errno == EAGAIN || errno == EWULDBLOCK)
perror("No data available\n");
else
// 真的出错了,那该怎么办呢?
}else if (ret1 == 0)// 对端关闭了连接
break;
else // 接收到了数据
doSomething();
int ret2 = recv(fd2, buf, sizeof(buf), 0);// 第二个IO
if (ret2 < 0){
if (errno == EINTR)
perror("Interruption\n");
else if(errno == EAGAIN || errno == EWULDBLOCK)
perror("No data available\n");
else
// 真的出错了,那该怎么办呢?
}else if (ret1 == 0)// 对端关闭了连接
break;
else // 接收到了数据
doSomething();
int ret3 ... ...;
nanosleep(sleep_interval, nullptr); // 下轮检测前睡眠片刻
}
上面这种实现缺点很明显:
- 循环的频次太低,会导致 IO 相应延迟;
- 循环的频次太高,每次都要循环 recv 检测所有文件;但是 recv 是个系统调用,对每个文件描述符都要返回一次,当需要并发处理的 IO 很多时,整体性能会变得很差。
实际上,上述的这种实现已经非常接近 select 这种 IO 多路复用了,只是要在用户层手写 while 轮询对每个文件单独的使用 recv 这种系统调用,整体效率不太划算。那么,更好的选择当然是使用操作系统提供的内核级别的实现。
read/write, recv/send 和阻塞/非阻塞
个人的理解,阻塞非阻塞对应的是文件描述符的性质,所以如上文介绍,非阻塞标志位的设定发生在启动 socket() 和 open() 语句中。但是在 socket 编程中,通常使用 recv 而不是 read 读数据、使用 send 而不是 write 写数据。相比于 read/write ,recv/send 多出一个 flags 参数:
int recv(int sockfd, void *buf, int len, int flags);
int send(int sockfd, void *buf, int len, int flags);
返回值大于零代表读到了部分或全部数据,其值代表实际读到了数据的字节数;若返回值为 0 表示已经读到文件结束;返回值小于 0 表示出现错误,调用带回错误码如 EWOULDBLOCK, EINTR 等等说明错误原因。
flags 参数可以是 0 或者下面诸项的组合:
| flags | description |
|---|---|
| MSG_DONTROUTE (仅 send) | 不查路由表,通常用于本局域网段内部发送消息 |
| MSG_PEEK (仅 recv) | 只查看,并不从系统缓冲区移走数据 |
| MSG_OOB | 接受或发送带外数据(啥意思??) |
| MSG_DONTWAIT | 临时将本次读写操作设置为非阻塞 |
| MSG_WAITALL (仅 recv) | 直到读到请求的数据字节数,才返回。(临时阻塞?) |
当 flags 设置为 0 时,recv/send 和 read/write 完全一致;当 flags 参数为 MAG_DONTWAIT 时,代表本次读写操作为非阻塞,也即无论当前打开的文件描述符被设置为阻塞还是非阻塞,本次调用后都不等待,立刻返回。
IO 多路复用技术,select, poll, epoll
IO 多路复用技术可以解决进程或线程阻塞到某个 IO 系统调用的问题,是进程或线程不阻塞于某个特定的 IO 系统调用。IO 多路复用通过一种机制可以使一个进程或线程监控多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),就能通知程序进行相应的读写操作。select, poll, epoll 都是 IO 多路复用的机制,和多线程/多进程或者非阻塞轮询方式相比,在高并发场景下 IO 多路复用拥有较高的效率优势。
比如相比于多线程实现,IO 多路复用由于所有的处理都在一个线程中进行,减小了线程上下文切换的开销;相比于非阻塞轮询,IO 多路复用可以一次处理一批文件描述符,整个过程都在内核中进行,处理完返回,而不是一个文件描述符一次系统调用,这样系统开销必然要小得多。
select
select 是操作系统提供的系统调用,它是 跨平台 的。通过它,我们可以一次性把一批文件描述符(文件描述符数组)发送给操作系统,让操作系统去遍历,确定那个文件描述符可用,然后我们去处理。
select 的原理和我们上文介绍的 非阻塞 IO + 轮询 在用户层面模拟 IO 多路复用的实现有些相似,但是整个轮询过程完全放入了内核空间,避免了每个文件操作符都要执行一次单独的系统调用的这个过程,这样一来必然减少了系统开销,提高了效率。
调用 select 后进程阻塞直到有就绪事件发生或者超时,函数返回。当 select 返回,遍历 fd_set 找到就绪的文件描述符进行相应的处理。
#include <sys/select.h>
int select( int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
- 功能:接收文件描述符数组,轮询 监视并等待多个文件描述符的属性变化(可读,可写,或错误异常),将就绪的文件描述符标记为就绪(可读/可写/异常等)。
- 参数:
- nfds:要监视的文件描述符的范围。
- readfds:受监视的可读文件描述符位图。
- writefds:受监视的可写文件描述符位图。
- exceptfds:受监视的异常文件描述符位图。
- timeout:超时时间。
- 返回值:成功则返回就绪描述符的数目,超时返回 0, 出错返回 -1。
更详细的解释:
nfds
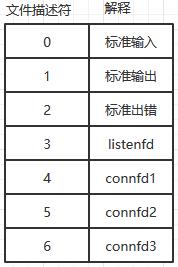
一般取监视的描述符的最大值加一。比如需要监视的文件描述符的最大值为 23,由于文件描述符总是从 0 开始,所以轮询检测到 23 号描述符之前,其前面的 0, 1, 2, …, 22 号都需要先被轮询监测,所以监视范围就应该是 23+1 = 24。
而且,虽然内核规定 select 可见时的最大范围是 1024 个文件件描述符,但实际网络通信中最大可监视数量理想情况应该是 1020,这是由于 0, 1, 2 这三个文件描述符 linux 自己要用,3 这个文件描述符一般是用来监听的套接字 socket,真正建立的连接的文件描述符理想情况下应该从 4 开始。如下图:
fd_set
fd_set 可以看作是一个存储文件操作符的集合,实际它存储的是文件操作符的句柄而不是操作符本身。fd_set 的大小只有 1024,这是由于其被定义为由 32 个 unsigned long 类型表示,每个 unsigned long 长度为 4 字节共 32 bits。这是系统写死的,要改变这个大小限制,需要改变这个定义,然后重新编译内核。
被 select 监控的文件描述符可以加入到不同的 fd_set 中,每个 fd_set 只会筛选出相应 IO 就绪的文件描述符。比如,connfd1 同时保存在 readfds 和 writefds ,但是其可读状态只会被 readfds 记录,其可写状态只会被 writefds 记录。
linux 下的 fd_set 是个1024 位的位图,当调用 select 的时候,内核根据 IO 状态修改 fd_set 的内容。位图是什么? 可以理解为一张 32*32 的表格,表格中的值非 0 即 1。位图中某位置元素值为 1,则代表该位置对应的文件描述符就绪。如下图:

依照该位图,第 320+3=3, 321+2=34, 和 32*2+1=65 号元素所对应的文件描述符就绪。
文件描述符本身和位图之间,可以使用下面四个宏产生关联:
void FD_ZERO(fd_set *fdset); // 清空集合 fdset
void FD_SET(int fd, fd_set *fdset); // 将文件描述符 fd 加入到集合 fdset 中
void FD_CLR(int fd, fd_set *fdset); // 将文件描述符 fd 从集合 fdset 中移除
void FD_ISSET(int fd, fd_set *fdset); // 检查文件描述符 fd 是否可读/可写/异常
timeout
一个结构体参数,定义位于 <sys/time.h>:
/*
#include <sys/time.h>
*/
struct timeval {
long tv_sec; // seconds
long tv_usec; // microseconds
}
该参数用来指定 select 阻塞的最长时间,可以设置为:
- nullptr: 一直阻塞,直到有文件描述符就绪。
- 0:也就是结构体内部两个值都是 0,非阻塞,立刻返回。有就绪返回数量,没有返回 0。
- 固定值:等待固定时间,这段时间内有文件描述符就绪则返回其数量,否则返回 0。
select 的优势:
- 相比于用户进程实现的非阻塞IO+轮询并发,select 既做到了一个线程处理多个客户端连接,又减少了系统调用的开销(多个文件描述符只有一次 select 系统调用 + n 次就绪状态的文件描述符的 recv 系统调用)。
- select 是跨平台的,几乎所有平台都有其实现。
select 的劣势:
- 每次调用 select 都需要把 fd_set 集合从用户态拷贝到内核态,然后再拷贝回用户空间,这个开销在 fd 很多时会很大;select 使用轮询的方法在内核遍历传递进来的所有 fd,而且只返回就绪文件描述符的数量,需要用户态再遍历一遍所有文件描述符以确定哪个文件描述符是就绪的,这个开销在 fd 很多时也会很大。
- 单个进程 能监视的文件描述符的数量存在最大限制,Linux 一般为 1024。这是系统写死的,要改变这一限制需要改变 fd_set 的定义,然后重新编译内核。但是由于上一条,该值越大,效率也就越低。
select + tcp demo
给出一段 tcp 服务端使用 select 的 demo:
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/select.h>
#include <arps/inet.h>
#include <errno.h>
#include <pthread.h>
#include <signal.h>
#include <ctype.h>
#include <vector>
using namespace std;
typedef struct {
int fd;
struct sockaddr_in addr;
} CLIENT;
int main(int argc, char **argv){
int lfd, cfd; // listenfd, connfd
socklen_t clt_addr_len; // for client socket
struct sockaddr_in serv_addr, clt_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); // equal to bzero(&serv_addr, 0);
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(8848);
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
int opt = 1;
setsocket(lfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
lfd = socket(AF_INET, SOCK_STREAM, 0);
bind(lfd, (struct sockaddr*)serv_addr, sizeof(serv_addr));
listen(lfd, 128);
fd_set rset, allset; // read fd_set, all fd_set
int maxfd = lfd;
FD_ZERO(&allset);
FD_SET(lfd, &allset);
char buf[1024];
CLIENT client[1024];
for (int i = 0; i < 1024; i++)
client[i].fd = -1, client[i].addr = nullptr;
for (;;){
rset = allset;
struct timeval timeout;
timeout.tv_sec = 2;
timeout.tv_usec= 0;
int nready = select(maxfd+1, &rset, nullptr, nullptr, &timeout);
if (nready < 0) {
perror("select error.\n");
exit(1);
}
if (nready == 0) {
perror("timeout.\n");
continue;
}
if (FD_ISSET(lfd, &rset)){// listenfd is ready, new connection arrived.
clt_addr_len = sizeof(clt_addr);
cfd = accept(lfd, (struct sockaddr*) &clt_addr, &clt_addr_len);
memset(buf, 0, 1024);
fprintf(stdout, "client connection: %s:%d\n",
inet_ntop(AF_INET, &clt_addr.sin_addr.s_addr, buf, 1024),
ntohs(clt_addr.sin_port));
FD_SET(cfd, &allsets);
for (int i = 0; i < 1024; i++){
if (client[i].fd == -1){
client[i].fd == cfd;
client[i].addr = clt_addr;
}
break;
}
maxfd = max(cfd, maxfd);
if (-- nready == 0) continue; // only lintenfd, no client connfd
}
for (int i = 0; i < 1024; i++){ // scan & check all fds in flag
if (cfd = client[i].fd < 0) continue;
if (FD_ISSET(clientfd, &rset)){ // read connfd flag[i] is ready
-- nready;
memset(buf, 0, 1024);
int ret = recv(flag[i], buf, sizeof(buf), 0);
//block, equal to read()
if (ret == -1) {
perror("recv error.\n");
continue; // error, skip it.
}
else if (ret == 0) { // client closed.
close(flag[i]);
fprintf(stdout, "client %s:%d closed.\n",
inet_ntop(AF_INET, &client[i].fd.sin_addr.s_addr, buf, sizeof(buf)),
ntohs(cient[i].fd.sin_port));
FD_CLR(flag[i], &allset);
continue;
}
for (int j = 0; j < ret; j++) buf[j] = toupper(buf[j]);
send(flag[i], buf, ret, 0); // block, equal to write()
write(STDOUT_FILENO, buf, ret);
// write into standard output, STDOUT_FILENO = 1
if (nready == 0) break;
}
}
}
close(lfd);
return 0;
}
根据以上介绍和代码,select 的执行流程如下图:
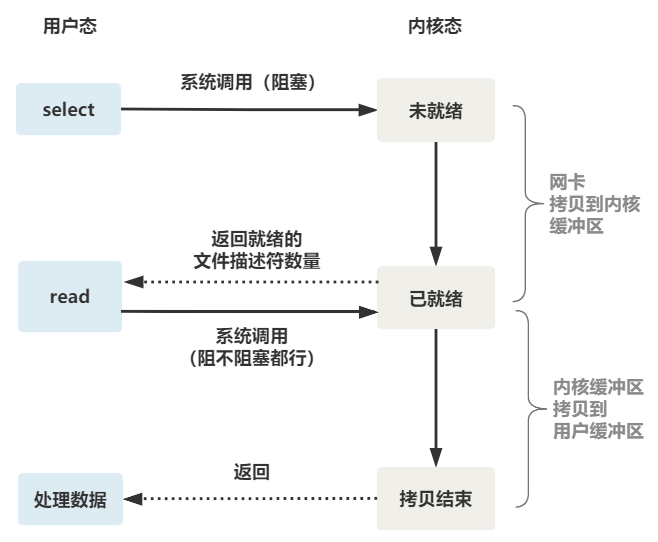
poll
poll 也是系统提供的系统调用。和 select 没有本质的区别,依然是将一组文件描述符拷贝到内核空间轮询,直到有事件就绪或者超时返回到用户空间。依然是返回 0 或者就绪事件的数量,依然要在返回后由用户进程再次遍历寻找就绪文件描述符进行处理。所不同的是, poll 可以检测更多类型的事件;poll 存储文件描述符的长度没有限制。
#include <poll.h>
int poll(struct pollfd *__fds, unsigned long __nfds, int __timeout);
功能:接收存有文件描述符的结构体数组,监测文件描述符状态变化,直到超时或有就绪的文件描述符。
select 区别:可以监控的事件类型更多,可以监控的文件描述符无限制,数组长度由用户规定而不是内核写死。
参数:
- __fds:指向一个结构体数组的指针,每个数组元素都是一个 pollfd 结构,数组长度有用户定义,无限制。
- __nfds:上面数组中有效元素的个数。
- __timeout:超时时间(毫秒数),0 表示不阻塞直接返回,-1 为永远等待直到返回。
返回值:>0 为就绪描述符的数量,=0 超时,<0 出错。
仔细看一看 struct pollfd 结构:
struct pollfd {
int fd; // 文件描述符
short int events; // 要监控的事件,值有对应宏
short int revents; // 返回时系统通过这个值告诉用户发生了什么,值有对应宏
}
对于 events/revents 这两个变量,常见的类型和 select 所能监控的一样,可读可写和错误异常:
#define POLLRDNORM 0x040;
#define POLLWRNORM 0x100;
#define POLLERR 0x008;
可以并列出现比如:POLLRDNORM|POLLWRNORM。
poll 的优势劣势和 select 没有本质差别,除了可以监控更多的文件描述符和不可跨平台。
poll 的优势:
- poll 同样做到了一个线程处理多个客户端连接的情况下,减少系统调用的开销(多个文件描述符只有一次 poll 系统调用 + n 次就绪状态的文件描述符的 recv 系统调用)。
poll 的劣势:
- 每次调用 poll 都需要把 pollfds 集合从用户态拷贝到内核态,然后再拷贝回用户空间,这个开销在 fd 很多时会很大;poll 使用轮训的方法在内核遍历传递进来的所有 fd,而且只返回就绪文件描述符的数量,需要用户态再遍历一遍查找那个事件是就绪的,这个开销在 fd 很多时也会很大。
- poll 不是跨平台的,只在 Linux 平台支持(存疑,没有绝对性证据支持,自己瞎猜)。
tcp + poll demo
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <poll.h>
#include <arpa/inet.h>
#define BACKLOG 5
#define BUFF_SIZE 200
#define DEFAULT_PORT 8848
#define OPEN_MAX 1024 // 可监控文件描述符最大数量,自定义,可以非常大。
using namespace std;
int main(int argc, char **argv) {
if (argc > 2){
perror("USAGE: %s <port>\n", argv[0]);
exit(1);
}
int serv_port = DEFAULT_PORT;
if (argc == 2) serv_port = atoi(argv[1]);
int lfd, cfd;
char buf[BUFF_SIZE];
struct sockaddr_in serv_addr, clt_addr;
socklen_t addr_len;
if (lfd = socket(AF_INET, SOCK_STREAM, 0) < 0){
perror("socket error.\n");
exit(1);
}
int opt = 1;
if (setsockopt(lfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)) < 0){
perror("setsockopt error.\n");
exit(1);
}
bzero(&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(serv_port);
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(lfd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0){
perror("bind error.\n");
exit(1);
}
if (listen(lfd, BACKLOG) < 0){
perror("listen error.\n");
exit(1);
}
struct pollfd client[OPEN_MAX];
client[0].fd = lfd;
client[0].events = POLLRDNORM;
for (int i = 1; i < OPEN_MAX; i++) client[i].fd = -1;
int maxi = 0;
for (;;){
int nready = poll(client, maxi+1, -1); // 超时-1, 恒阻塞
if (nready < 0){
perror("poll errpr.\n");
exit(1);
}
if (client[0].revents & POLLRDNORM){ // 来了一条新连接
addr_len = sizeof(clt_addr);
if (cfd = accept(lfd, (struct sockaddr*) &clt_addr, &addr_len) < 0){
perror("accept error.\n");
exit(1);
}
int i;
for (i = 1; i < OPEN_MAX; i++){
if (client[i].fd == -1){
client[i].fd = cfd;
client[i].events = POLLRDNORM;
break;
}
}
maxi = max(maxi, i);
if (--nready == 0) continue;
}
for (int i = 1; i < max_i; i++){
if (cfd = client[i].fd == -1) continue;
if (client[i].revents & (POLLRDNORN | POLLERR)){
-- nready;
memset(buf, 0, BUFF_SIZE);
ssize_t ret = recv(cfd, buf, BUFF_SIZE, 0);
if (ret < 0){
perror("recv error.\n");
continue;
}
else if (ret == 0){
printf("client[%d]: fd=%d closed.\n", i, cfd);
close(cfd);
client[i].fd = -1;
continue;
}
for (int j = -; j < ret; j ++) buf[j] = toupper(buf[j]);
send(cfd, buf, ret, 0);
write(STDOUT_FILENO, buf, ret);
if (nready == 0) break;
}
}
}
close(lfd);
return 0;
}
显然,除了 API 调用和部分参数细节上与 select 存在些许差别外,poll 整体的使用流程和 select 相差无几。
epoll
poll 虽然解决了 select 的描述符数量限制,但是其实现机制仍然是把用户态的描述符数组打包拷贝到内核态,在内核完成轮询后全部吐出来,再由用户手动遍历查询一遍。在性能上并没有提升。且随着描述符数量增长,其性能也会大幅下降。epoll 机制从根本上解决了上述问题。
epoll 是 event poll 的简称,是 Linux 提供特有的事件驱动的 IO 多路复用机制。epoll 不是一个单独的调用,而是一组系统调用的统称,包括:
- epoll_create
int epoll_create(int __sizex); int epoll_create1(int __flags);创建一个新的 epoll 实例,并返回该实例的描述符(句柄)。此两者功能相同,在 linux2-6 版本内核之后,epoll_create(int __size) 的 size 参数不再具有意义,只要大于零,效果都一样。实际上,前者在具体实现上是调用了后者 epoll_create1(int __flags) ,后者的 flag 参数可以设置为 0 或
EPOLL_CLOEXEC,这个选项的作用是,当父进程 fork 出一个子进程的时候,子进程不会包含 epoll 的文件描述符。 - epoll_ctl
int epoll_ctl(int __epfd, int _op, int __fd, struct epoll_event *__event);向 epoll_fd 添加、修改或删除事件,成功返回 0,失败返回 -1 并带回错误码 errno。
参数:- epfd: epoll_create() 返回的句柄。
- op: 具体操作。
EPOLL_CTL_ADD注册新的 fd 到 epfd 中
EPOLL_CTL_MOD修改已注册的 fd
EPOLL_CTL_DEL从 epfd 中删除一个 fd - fd: 被操作文件描述符。
- event:高速告知内核需要监听什么类型事件的结构体(给地址)。定义如下:
struct epoll_event{ __uint32_t events; epoll_data_t data; }其中
__uint32_t events指明了感兴趣的事件类型,包含:value description EPOLLIN 可读(包括对端正常关闭) EPOLLOUT 可写 EPOLLPRI 紧急可读(外带数据?什么意思?) EPOLLERR 发生错误 EPOLLHUP 对应 fd 被挂起 EPOLLET 将 epoll 设置为边缘触发模式 EPOLLONESHOT 只监听一次,完成本次监听后如需要继续监听该 fd,需要再次添加 epoll_data data是个指明了具体事件(地址,或描述符等)的联合体,定义为:typedef union epoll_data{ void *ptr; int fd; uint32_t u32; uint64_t u64; }epoll_data_t;应该和具体的使用方式有关。
- epoll_wait
int epoll_wait(int __epfd, struct epoll_event *__events, int __max_events, int __timeout);监听 epfd 中的 IO 事件,没有就绪则阻塞线程,直到超时或者有 IO 就绪,返回就绪事件 IO 的数量,或者 0(无就绪),或者 -1 (发生错误)并带回错误码。
参数:- epfd: epoll 句柄。
- events: 就绪事件结构体数组。epoll 会将本次监听发生的就绪事件结构体返回到该数组中。
events 不可以是空指针内核只负责把数据复制到这个 events 数组中,不负责在用户态分配内存,这样效率很高。
epoll 将就绪链表中数据从内核返回到用户态的过程,使用 mmap 使得用户空间和内核空间共享同一块物理地址实现,减少了不必要的拷贝,这样做效率非常高。 - max_events:本次可以返回的最大事件数目,通常和预先分配的 events 数组大小一致。
- timeout: 超时时间,毫秒。
epoll 原理:
epoll 在初始化时会注册一个单独的文件系统 eventpoll,同时在内核空间开辟一个单独的、专用的高速 cache 区:连续的物理内存页,并在这个高速 cache 区建立红黑树和就绪链表。被监控文件描述符存放于该红黑树,就绪事件描述符则加入到就绪链表。
eventpoll 是一个结构体,定义如下:
struct eventpoll {
spin_lock_t lock;
struct mutex mtx;
wait_queue_head_t wq;
wait_queue_head_t poll_wait;
struct list_head rdllist; //就绪链表
struct rb_root rbr; //红黑树根节点
struct epitem *ovflist;
}
使用 epoll_ctl 向 epollfd 添加一个新的文件描述符时,实际是将该文件描述符挂载到内核高速缓存区的红黑上。这样新到的文件描述符 fd 就已经在内核态了,那么我们调用 epoll _wairt 的时候就不需要进行一次额外的用户态向内核态的拷贝了。
所有添加到 epoll 中的事件都会与设备(如网卡)驱动程序建立回调关系,也就是相应事件发生时会调用这里的回调方法:ep_poll_callback ,该回调方法就会把事件加入到就绪链表中。
epoll 对每个事件都会建立一个 epitem 结构体,存储着加入 epoll 的事件的信息:
struct epitem {
struct rb_node rbn; // 红黑树节点
struct list_head rdllink; // 就绪链表(双向)节点
struct epitem *next;
struct epoll_filefd ffd; // 事件句柄信息
int nwait;
struct list_head pwqlist;
struct eventpoll *ep; // 指向其所属的 eventpoll 对象
struct list_head fllink;
struct epoll_event event; // 感兴趣的事件类型
}
调用 epoll_wait 执行监测时,则只需要观察 eventpoll 对象包含的就绪链表 rdlist 中是否有 epitem 即可。有数据就返回,没有数据就 sleep 直到 timeout 。返回,指的是将 rdlist 链表中的事件复制到用户空间,并返回事件数量。
总结
- 一颗红黑树,一个就绪事件链表,少量的内核 cache,高效解决高并发问题。
- epoll_create():建立 eventpoll 对象,开辟内核高速 cache 区,cache 中创建红黑树和就绪链表。
- epoll_ctl():如果增加 socket 句柄,则检查位于内核 cache 区的红黑树中是否存在对应 epitem,存在立刻返回,不存在则加入树中,并向内核注册回调函数,用于当中断事件来临时向就绪链表添加数据。
- epoll_wait():检查就绪链表 rdlist,有数据立刻返回,没有数据等待直到 timeout。
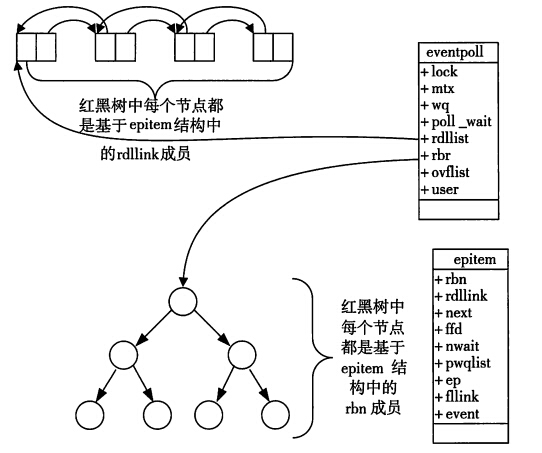
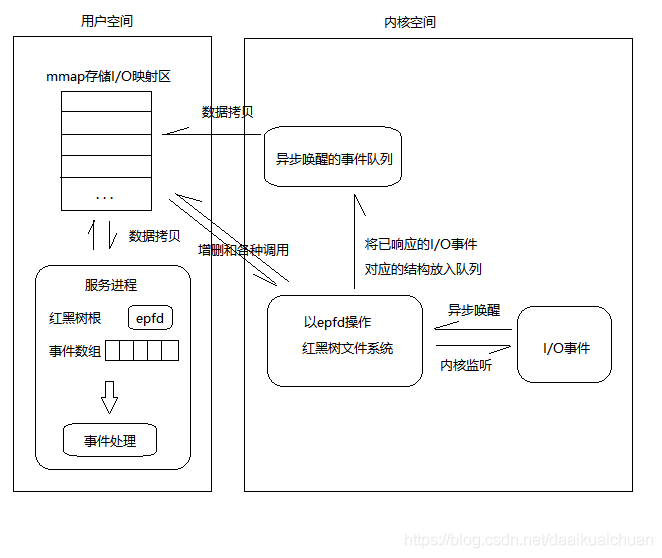
epoll + tcp demo
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/epoll.h>
#define MAX_EVENTS 1024 // 自定义最大可接受连接数,可以很大,无限制
int main(int argc, char **arvg){
if (argc > 2){
perror("USAGE: %s <port>\n", argv[0]);
exit(1);
}
int port = 8848;
if (argc == 2) port = satoi(argv[1]);
int lfd, cfd;
int epollfd;
int ret;
cahr buffer[1024];
socklen_t addr_len;
struct sockaddr_in serv_addr, clt_addr;
struct epoll_event ev, ready_events[MAX_EVENTS];
if (lfd = socket(AF_INET, SOCK_STREAM, 0) < 0){
perror("socket error.\n");
exit(1);
}
int opt = 1;
if (setsockopt(lfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)) < 0){
perror("setsockopt error.\n");
exit(1);
}
bzero(&serv_addr, sizeof serv_addr);
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(port);
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(lfd, (struct sockaddr *) &serv_addr, sizeof serv_addr) < 0){
perror("bind error.\n");
exit(1);
}
if (listen(lfd, 128) < 0){
perror("listen error.\n");
exit(1);
}
if (epollfd = epoll_create1(0) < 0){
perror("epoll_create error.\n");
exit(1);
}
ev.events = EPOLLIN;
ev.data.fd = lfd;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, lfd, &ev) < 0){
perror("epoll_ctl error.\n");
exit(1);
}
for (;;){
int nready;
if (nready = epoll_wait(epollfd, ready_events, MAX_EVENTS, -1) < 0){
perror("epoll_wait error.\n");
exit(1);
}
for (int i = 0; i < nready; i++){
if (ready_events[i].data.fd == lfd){
if (cfd = accept(lfd, (struct sockaddr*) &clt_addr, &addr_len) < 0){
perror("accept error.\n");
exit(1);
}
fprintf(stdout, "\nNew client connections client[%d] %s:d\n",
cfd, inet_ntoa(clt_addr.sin_addr), ntohs(clt_addr.sin_port));
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = cfd;
if (epoll_ctl(epollfd, EPOLL_CLT_ADD, cfd, &ev) < 0){
perror("epoll_ctl error.\n");
exit(1);
}
}else if (ready_events[i].events & EPOLLIN){
cfd = ready_events[i].data.fd;
memset(buffer, 0, sizeof buffer); // bzero(buffer, sizeof buffer);
if (ret = recv(cfd, buffer, sizeof buffer, 0) < 0){
perror("recv error.\n");
exit(1);
}
else if (ret == 0){ // 对端正常关闭
fprintf(stdout, "\nDisconnect fd[%d]\n", cfd);
close(cfd); // epoll 会自动移除该文件描述符,如果不放心还可以跟一步
epoll_ctl(epollfd, EPOLL_CTL_DEL, cfd, nullptr);
}else{
for (int i = 0; i < ret; i ++) buffer[i] = toupper(buffer[i]);
if (send(cfd, buffer, ret, , 0) < 0){
perror("send error.\n");
exit(1);
}
if ( write(STDOUT_FILENO, buffer, ret) < 0){
perror("write error.\n");
exit(1);
}
}
}else continue;
}
}
close(lfd);
return 0;
}
事件触发模式,ET 和 LT
ET (Edge Triggered,边缘触发) 和 LT (Level Triggered,水平触发) 是两种事件触发模式,区别在于触发时机不同。
ET: 仅当内核缓冲区有 正向变化 或事件类型发生变化的时候,返回就绪事件。形象一点说:
对于读操作,当
- 读缓冲区由不可读变为可读,即缓冲区由空变为不空。
- 有新数据到达,即缓冲区内数据变多。
- 读缓冲区内有数据可读,且应用进程将对应文件描述符修改为 EPOLLIN 。
的时候,返回对应的读就绪事件。而一种典型的情况,缓存区有数据但是本次未读出或者未完全读出,此时虽然缓存区仍留有数据,但 ET 不会触发,不会返回读就绪。
对于写操作,当
- 写缓冲区由不可写变为可写,也即缓冲区由满变为不满。
- 旧数据被写出,即缓存区的内容变少、可写空间变多。
- 写缓冲区有空间可写,且应用进程将对应文件描述符修改为 EPOLLOUT。
的时候,返回对应的写就绪事件。一种典型的情况,缓存区有空间可写,但是数据没有写出或数据有增多但未满,此时虽然缓存区仍留有空间,但 ET 不会触发,不会返回写就绪。
LT: 简单粗暴,只要缓存区有数据,一直返回读就绪;只要缓存区有空间,一只返回写就绪。
select, poll, epoll 三种多路复用机制都支持 LT 模式,而 ET 模式只有 epoll 支持。
LT 也是 epoll 机制的缺省事件触发模式,这可能是由于 LT 同时支持阻塞和非阻塞,且实现起来更加简洁的原因。
LT 和 ET 在实现上的区别
已知,对于 epoll 而言,就绪事件加入到就绪事件链表是通过和驱动绑定的回调函数实现的,驱动上有事件发生时会告知 epoll 将相应文件描述符添加到就绪事件链表;epoll_wait 调用会检查就绪事件链表是否有数据以及每个描述符上是否有真的有事件。
LT 和 ET 的区别就在于 epoll_wait() 函数调用的过程上,如果事件是 ET 模式,则 epoll_wait() 在检查完该事件后会将改事件移除就绪链表;如果是 LT 模式,则会将其留在就绪事件链表,等到下一轮检查如果缓存区被读完或者被写满,也即描述符中没有可读可写事件,则该描述符也会被移除就绪链表,并且不作为就绪事件返回。
为什么 ET 一定要工作在非阻塞模式
使用 ET 模式一定要使用非阻塞 IO, 这是因为:
已知,ET 模式下我们需要一次性处理完就绪文件描述符上的全部数据,比如使用 recv/read 或者 send/write 直到返回 EAGAIN,若将文件描述符设置为阻塞,那么程序一定会在最后一次 write/send 或 read/recv 阻塞朱,这样程序就不能在 epoll_wait 阻塞了,那么就会导致其他文件描述符的饥饿问题,也即,读不到写不出。因此,一定要在 ET 模式下使用非阻塞 IO。
epoll 和 poll/select 的对比
- 用户态将文件描述符传入内核的方式
- select:创建 3 个文件描述符集合并拷贝到内核中,分别监听读写和异常。其中文件描述符集合是数组构成的位图,每个 0/1 比特位存放一个文件描述符,长度固定为 1024 。
- poll:文件描述符存储在 pollfd 结构体中,将该结构体数组拷贝到内核。结构体数组长度不受限。
- epoll:执行 epoll_create 就会在内核开辟专属告诉 cache 并创建一颗红黑树和就绪链表。用户通过 epoll_ctl 添加文件描述符直接在内核红黑树中添加相应节点。
- 内核态检测文件描述符读写状态的方式
- select:轮询。遍历文件描述符 fd_set 数组,并通过掩码的方式将 fd_set 中相应元素赋值。
- poll:轮询。遍历 pollfd 结构体数组,将就绪状态写会 pollfd 的 revents 变量。
- epoll:采用异步回调机制。执行 epoll_ctl 添加文件描述符的时候,向红黑树添加新的节点的同时,注册一个和驱动链接的回调函数,当对应驱动上有时间发生的时候(如键盘输入、网卡数据到达),该回调函数被调用,并将对应的文件描述符的 epitem 事件添加到就绪链表。
- 找到就绪文件描述符并传递给用户态的方式
- select:将传入的 fd_set 整体拷贝回用户态并返回就绪事件总数。但是用户态并不知道哪些文件是就绪的,仍需要再遍历一遍。
- poll:将传入的 pollfd 结构体数组整体拷贝回用户态并返回就绪事件总数。但是用户态并不知道那些文件是就绪的,仍然需要再遍历一遍。
- epoll:epoll_wait 检查就绪链表是否有数据,若有数据则将链表内数据返回到 epoll_events 结构体类型数组,并返回就绪事件总数。用户态接收到的时间都是就绪的,只需要依次处理而不需要遍历数组。特别的,数据返回给用户空间这一过程通过 mmap 让内核和用户控件共享同一块物理内存而实现,减少了不必要的拷贝。
- 重复监听的处理方式
- select:更新文件描述符集合,继续上述完整拷贝整个集合等步骤。
- poll:更新 pollfd 结构体数组,继续上述完整拷贝整个数组等步骤。
- epoll: 不需要完整拷贝,在原有的红黑树上增删改节点即可。
epoll 为什么高效
- select 和 poll 动作基本一致,只是 select 使用定长数组(位图),而 poll 采用结构体数组(在用户态)和链表(内核态)存储文件描述符,从而 select 能监听的文件描述符有最大链接数限制,而 poll 没有。
- select, poll, epoll 虽然都会返回就绪的文件描述符,但 select 和 poll 不会明确指出哪些文件描述符就绪,而 epoll 会。造成的区别就是,系统调用返回后,select 和 poll 仍然需要用户进程再遍历一遍返回来的整个儿文件描述符数组找到哪个文件描述符就绪,而 epoll 直接依次处理即可。
- select, poll 都需要将存储文件描述符的数据结构拷贝进内核,再拷贝回用户态。而 epoll 创建的存储文件描述符的数据结构本身就在内核态中,系统调用是不需要拷贝,返回时利用 mmap 将用户态和内核态映射到同一片物理内存空间,也不需要拷贝,减少了内核态和用户态之间的拷贝开销。
- select, poll 在内核态采用轮训的方式检查事件是否就绪,而 epoll 采用回调函数。造成的结果,随着监听文件描述符的增加, select 和 poll 的效率会先行降低,而 epoll 不会受到太大影响。
- select 和 poll 采用 LT 水平触发模式,有事件则一直触发;而 epoll 可以选用 ET 边缘触发模式,不会充斥大量不关心的文件描述符。
在大部分连接都十分活跃的情况下,epoll 的效率不一定比 select 和 poll 好,因为回调函数的调用需要额外的时间。
fork(), vfork(), clone(),写时复制技术和进程执行
Linux 的用户进程不能被直接创建出来,因为不存在这样的 API,只能从某个进程中复制出来,再通过 exec 这样的 API 切换到实际想要运行的进程。Linux 提供的复制出新进程的 API 有三种:fork, vfork, clone。三个系统调用最终通过 do_fork() 函数实现。
| 系统调用 | 描述 |
| :—- | :—- |
| fork | 子进程完全拷贝父进程,包括 进程控制块(Processor Control Block, PCB),进程程序块(可以和其他进程共用),进程数据块(进程的专属空间,用于存放各种私有数据和堆栈空间等),独立的空间(如果没有这一项,则被认为是线程) 。
父子进程的执行先后次序是不确定的。 |
| vfork | 子进程与父进程共享进程数据块。
vfork 保证子进程先于父进程执行,在子进程调用 exec 或 exit 之前,父进程不执行。如果在调用这两个函数之前子进程依赖与父进程的进一步动作,会导致死锁。 |
| clone | clone 是有参数的系统调用,功能更多样性更复杂。clone 允许用户通过参数主动选择子进程拷贝或共享父进程的哪些资源,比如可以指定子进程与父进程共享用户空间从而使复制出来的是一个线程。 |
fork()
fork() 复制一个新进程时,是完全拷贝而不是共享父进程的其他资源。如父进程打开了五个文件,那么子进程也有五个打开的文件,且这些文件当前的读写指针也停在相同的地方。这样得到的子进程完全独立与父进程,具有良好的并发性,但而知之间的通讯需要专门的通信机制,如 管道 pipe、共享内存等等。
但是程序正文段,子进程是与父进程共享的。程序正文段包含着CPU 执行的机器码,通常是只读的。
通过 fork 复制新进程需要完全复制父进程中的所有资源,这是一笔不小的开销,尤其是其中的用户空间,是相对庞大的。但是这种开销往往是不必要的的,因为大部分情况下 fork 复制出一个新进程的目的仅仅是马上通过 exec 系统调用执行另一个可执行文件,这意味着 fork 过程中对父进程资源的完全复制、尤其是对用户空间的复制,是一种浪费行为。Linux 现在通过 Copy-On-Write 写时复制 技术降低了这一开销。
fork 调用后返回两个值:对父进程, fork 返回子进程的进程号 pid,对子进程,返回零。从而可以通过 fork 的返回值判断当前所执行的是父进程还是子进程。对父进程返回子进程号、子进程返回零,是因为一个进程可能有很多子进程,但是它的父进程是唯一的,有且只有一个。于是父进程若在 fork 执行的时候无法获取当前 fork 出来的子进程的进程号,此后将很难获取;而子进程则可以通过 get_ppid() 随时获取父进程的进程号。
fork 出来的子进程和父进程哪一个先执行,依赖于操作系统的调度算法。
vfork()
vfork() 复制出一个新的子进程,子进程和父进程共享地址空间,或者说共享进程数据段。子进程修改了某个变量,等效于修改了父进程中的同名变量。因为父子进程共享地址空间,两个进程中的同名变量本质上就是同一个(具有相同物理地址)的变量。
vfork 避免了大量的进程资源拷贝造成的不必要的开销,在子进程仅仅被用来执行 exec 的场景下是非常高效的。实际上, vfork 的唯一目的就是执行完产生新的子进程后立刻 exec() 执行其它进程。出于这个目的,vfork 保证子进程优先执行,且在子进程调用 exec() 或 exit() 之前,父进程处于挂起状态。 也由于以上,使用 vfork 应保证复制出子进程后立刻 exec() 或 exit() ,并避免执行写操作,因为这会影响到父进程。
使用 vfork 复制出的子进程,只能使用 exit 退出,否则子进程将不能结束; fork 不存在这种情限制。
exec
exec 并不是一个函数,而是一组函数的统称。exec 函数组定义在 unistd.h 头文件中,包含六个具体的函数:
#include <unistd.h>
int execl(const char *path, const char* arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
其中:
- l 后缀:命令参数部分必须以逗号分隔,最后一个命令参数必须是 NULL。
- v 后缀:命令参数部分必须是一个以 NULL 结尾的字符串指针数组的头指针。
- p 后缀:执行文件 部分可以不带路径,exec 自行在 $PATH 中寻找。
- e 后缀:参数必须带环境变量部分,比较少用。
使用 fork 或 vfork 等系统调用复制出新的子进程后,子进程往往用于调用 exec() 执行另一个程序。exec() 是一种系统调用,当一个进程调用一种 exec() 族函数,新的可执行文件被装载到调用该函数的进程(往往是子进程)的地址空间,并从 main() 函数开始执行。
exec 并不创建新进程,所以调用前后的进程 id 不会改变,exec 只是使用一个全新的程序替换掉当前进程的代码段和数据段(堆段、栈段等)。
总结fork() 和 vfork() 的区别
- fork() 是对父进程包括内存空间等资源在内的完全拷贝,vfork() 则共享父进程的内存空间,相当于创建了一个线程,唯一目的就是用来 exec() 执行其他任务。
- fork() 之后父子进程的运行顺序不确定,但是 vfork() 保证子进程优先执行,直到子进程调用 exec() 或者 exit() 后父进程才开始运行,在此期间父进程使被阻塞的。
COW, Copy On Write, 写时复制技术
写时复制技术是用于解决 fork 调用产生多余开销的一种机制。由于 fork 复制出的子进程往往仅用于立刻调用 exec 加载一个新进程,并不会使用到复制出来的父进程的用户空间数据。于是完整复制父进程的用户空间,是完全多余的、不必要的开销。Linux 采用写时复制技术避免了这种浪费。具体的,fork 执行时,并不真正复制用户控件的所有页面,而只复制页面表。只有当随后父进程或子进程对某一块空间发生写操作时,才会引发“写复制”,将实际发生写操作的内存页 复制出一份新的可用空间分配给子进程,使其完全独立。
进程控制块 PCB 结构体 task_struct
进程控制块是系统为了管理进程设置的一个专门的的数据结构,主要表示进程状态。每个进程都对应一个 PCB 来维护进程相关的信息,在 Linux 中,PCB 结构为 task_struct 结构体。task_struct 是 Linux 内核的一种数据结构,存放在内核空间中。 包含了进程的信息主要如下:
- 进程状态。包括 可运行、可中断的等待状态、不可中断的等待状态、僵死、暂停、换入换出。
- 标识符。包括本进程标识符 pid、父进程标识符 ppid、用户标识符 uid / 组标识符 gid、有效用户标识符 euid /有效组标识符 egid 、备份用户标识符 suid / 备份组标识符 sgid、文件系统用户标识符 fsuid / 文件系统组标识符 fsgid 。
- 进程调度信息。通常包括进程的类别(实时还是普通)、进程优先级等等。
- 程序计数器。程序中即将被执行的下一条指令的地址。
- 内存指针。程序代码和进程相关的数据指针,与其他进程共享的内存快指针。
- 处理器相关的上下文数据。程序执行时处理器中的寄存器中的数据。
- IO 状态信息。
- 记账信息。 包括处理器时间总和、使用时钟数总和、时间限制、记账号等。
内存管理,页、页表、页表项
单进成操作系统,或者不严谨一点,如没有操作系统的天然单进程体系单片机,是可以直接操作硬件地址的,因为整个控制板上只有一个程序,不会发生地址冲突的情况。
但现代操作系统都是多进程系统,考虑一种情况,一个进程对一段物理地址进行了读写修改,而这一段物理地址却恰恰是另一个进程的代码地址段,则进程会立刻崩溃。为了避免这种情况,我们需要把进程所使用的物理地址隔离开来:让操作系统为内个进程分配一套单独的 虚拟地址,进程在虚拟地址里运行。操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来,当需要访问物理地址的时候,由操作系统将虚拟地址转换成物理地址。这样不同进程运行的时候读写修改的是不同的物理地址,就不会发生冲突了。
内存管理就是操作系统管理虚拟地址和物理地址之间的关系的方式,主要有分段和分页两种方式。
内存的分段管理
一个程序由若干个逻辑分段组成,如代码分段、数据分段、栈段、堆段等等,不同段是有不同属性的,可以用分段的形式将这些段分离出来。分段机制下,虚拟地址由两部分组成:段选择子和段内偏移量。
- 段选择因子:保存在段寄存器内,包含段号和标志位等信息,其中最重要的是段号,用作段表的索引。段表 里面保存着这个段的 基地址、段的界限、特权等级 等信息。
- 段内偏移量:介于 0 和段界限之间,如果段内偏移量是合法的,则虚拟地址对应的物理地址就是段基地址加上段内偏移量。
分段机制下,程序每一个段所对应的物理地址是连续的。连续的地址往往会产生 内存碎片 问题,解决内存碎片问题常用到内存交换,从而又带来 内存交换效率低 的问题。
内存碎片是什么?
考虑有多个程序采用分段式内存管理,从低到高占据了 连续的内存空间为: A 200Mb, B 400Mb,C 200Mb,现在 A,C 程序退出,有 400Mb 的内存被释放,但此时却无法启动一个 300 Mb 的程序(假定内存总空间只有 800 Mb),因为两段 200Mb 共 400Mb 的内存空间是被分割开的,无法有效利用。这就是内存碎片。
内存交换是什么?
我们回顾上面介绍的内存碎片的产生过程:
| 内存空间 | 0 - 200Mb | 200Mb - 600Mb | 600Mb - 800Mb|
| :— | :—| :—| :— |
|开始|A|B|C|
|然后| 空 | B | 空 |
|加载新程序?| < 300 Mb| B | < 300Mb |
怎么利用空出来的 600M 空间呢?可以将 B 程序占用的 400Mb 内存写到硬盘上,再读回到内存中。当然,再读回的时候肯定不能读到原来的位置,可以读回到比原来占据空间更低的空出的地址起点,也即 0 位置,从而空余出连续的 400Mb 空间,就可以装载新程序了。
硬盘里这块用于交换内存的空间,在 Linux 系统中,就是 Swap 空间。这也是我们通常将 Swap 设置为何内存一样大小的原因。
多进程系统中,采用内存分段的方式会很频繁的产生内存碎片,于是就不得不频繁的进行内存换入换出。但是,硬盘的访问速度远低于内存, sawp 的效率并不高,甚至成为多进程系统的性能瓶颈之一。
内存的分页管理
分段的好处是可以使程序运行在连续的内存空间中,但是会产生内存碎片、且内存交换效率低。
怎么从机制上解决以上问题呢?也就是,一方面减少内存碎片的产生,另一方面需要进行内存交换的时候,让需要写入祸从磁盘装载的数据更少一些?答案是内存分页管理。
分也就是把整个虚拟和物理内存空间切成一段段连续且固定尺寸的小空间,称为 页 。Linux 下,每一页的大小为 4KB 。虚拟地址和物理地址之间通过页表来映射。每个进程有一张页表,虚拟每一页虚拟内存空间通过页表中的一个页表项 映射到一个实际的物理空间页。Linux 采用的是页式内存管理机制。页表在内核空间中。
分页机制下,虚拟地址分为两部分:页号 和 页内偏移量 。页号作为页表中页表项的索引,页表包含了物理页每一页所在的物理内存的基地址这个基地址和页内偏移量共同组成实际的物理地址。当进程访问的虚拟地址在页表中查不到时,系统为进程分配新的物理内存并更新页表项,然后继续用户进程。
内存的分页管理机制怎样避免内存碎片、交换效率低等问题?
分页管理机制下,内存空间是预先划分好的,不会像分段那样产生间隙非常小的内存:后者正是分段会产生内存碎片的原因。而分页管理机制下,释放内存和分配内存都是以页为单位进行,不要求一定有一块能完整容纳进程的大块的连续内存空间,也就不会产生空间无法有效利用的问题。
如果内存空间不够,操作系统会把其他正在运行的进程中的 最近没有被使用 的内存页面释放掉,也就是暂时写到硬盘上,称为 换出;一旦需要的时候在加载进内存,称为 换入 。所以,一次性写入磁盘的只有少数的一个或几个页,不会花费太多时间,内存交换的效率就比较高。
更进一步地,分页的方式使得我们在加载程序的时候不再需要一次性把整个程序都加载到物理内存中,而被允许在完成虚拟内存页和物理内存页之间的映射之后,并不真的把页内容加载到物理内存中,而只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存中。
分页管理机制有什么缺陷?
分页管理机制有效避免了内存碎片和交换效率低的问题,但是存在空间占用上的缺陷。
32 位环境下,虚拟内存地址共有 4GB (2^32 B), 每个页的大小是 4KB (2^12 B),那么就需要 1 M (2^20) 个页,页表项需要能映射到任意一个页,也就是需要四个字节大小 (4B) 的空间。那么一个进程中的页表就需要 4B * 1M = 4MB 的空间。
但多进程系统往往会同时运行多个进程,每个进程都有自己的虚拟地址空间,也当然有一张自己独立的页表。那么 100 个进程的话,就需要 400MB 的内存被页表占据。
可以通过多级页表解决上面的问题,此处不多赘述。
段页式内存管理
内存的分段管理和分页管理并不总是对立的,他们也可以组合起来在同一个系统中使用。段页式内存管理,先将程序划分为具有不同逻辑意义的多个空间连续的段(代码段、数据段、堆段、栈段等),每个段内再划分为多个固定大小的页。
段叶式内存管理机制下,虚拟地址由段号、段内页号和页内偏移量三部分组成。每个进程拥有一张段表,每个段内又建立一张页表。段表中的地址是页表的起始地址,页表中页表项则映射到实际的物理内存页的地址。
守护进程 Daemon
守护进程(Daemon)是一种长期驻存于系统后台的非交互型进程,它独立于控制终端,并且周期性地执行或等待某些任务。Linux 服务端进程大都通过守护进程实现,如 httpd (web 服务端),mysqld (MySQL 服务端), sshd (ssh 服务端)等。守护进程的父进程是 init 进程(pid = 1,Linux 一号进程,内核启动后的第一个用户级进程,功能之一即是接管孤儿进程),因为它的父进程在 fork 之后就退出了。
守护进程是非交互型进程,没有控制终端、不产生任何输出(包括标准输出 stdout 和标准错误 stderr)。
守护进程一般在系统启动时开始运行,除非强行终止,否则直到系统关机都保持运行。
守护进程的创建
预备知识:
- 进程组(group): 进程组中可以包括一个或多个进程;一个进程一定属于一个进程组,并拥有一个进程组 ID,该 ID 为进程组长 PID;创建该进程组的进程为该进程进程组长。只要进程组中有一个进程存在,该进程组就是存在的,与进程组长是否终止无关, setpgid() 可用来创建一个新的进程组或改变进程默认所属的进程组,非 root 进程只能改变自己或自己创建的子进程的进程组。
- 会话(session): 多个进程组 构成一个会话,在会话中 进程组称为作业。创建会话的进程称为会话首进程。该进程的 PID 为该会话的 SID;一个会话可以拥有一个控制终端,终端的输入输出都会传给前台进程组,其他进程组为后台作业。 会话的意义在于将多个进程组通过一个控制终端控制,一个前台操作,其他后台运行。
一个典型的会话情形是 linux 的远程登录,每个远程登录 终端都是一个会话,一个会话里面允许多个进程组 (作业)同时工作,其中只有一个为前台,可以接收终端的标准输入输出,其他进程组都是后台作业。
setsid() 可以用来创建一个新的会话。若调用该函数的进程不是一个组长进程,则该调用产生一个新会话且:- 该进程成为新的会话首进程,且是该会话中的唯一进程。
- 该进程退出原来的进程组,成为新的进程组的组长进程。新进程组的 PGID 也即该进程的 PID。
- 该进程丢弃原来的控制终端(如果有的话),该会话没有控制终端。
若调用 setsid() 的进程是一个组长进程,则该调用返回错误。
创建守护进程的流程:
- 父进程 fork() 出子进程后 exit() 退出,子进程成为非组长进程。
- 子进程调用 setsid() 函数创建新会话,成为会话首进程。
- 子进程 fork() 出子子进程后 exit() 退出,子子进程不是会话首进程,防止其获取终端控制权。
- 子子进程调用 umask() 将文件模式创建屏蔽字设置为 0。 这是因为守护进程可能需要创建一个组可读可写的文件,而继承来的文件模式创建屏蔽字可能屏蔽了这两种权限。
- 子子进程调用 chdir() 将工作目录社转移到根目录。这是由于从父进程继承来的工作目录可能在一个装配文件系统,这样的话守护进程也会一直工作在这个装配文件系统里,则该装配文件系统便不可拆卸。这与装配文件系统的愿意不符。
- 子子进程关闭自父进程继承来、但不再需要的文件描述符(本地、网络)。
- 子子进程重定向 0, 1, 2 (标准输入 stdin,标准输出 stdout,标准错误 stderr) 文件描述符到空设备
/dev/null,使其失去输入输出。 - 得到一个守护进程。
- 守护进程的关闭:一般使用 Kill 杀掉。
守护进程和用 & 结尾的后台运行程序有什么差别?
- 守护进程完全脱离终端,后台程序则不然,在终端关闭之前还是会打印信息。
- 守护进程在终端关闭时不受影响,后台程序则会随用户退出而退出。需要手动指定
nohup不挂断。 - 守护进程的会话组、当前目录、文件描述符等都是独立的。后台运行则不是独立的,只是终端进行了一次 fork 将程序放到后台。
- 使用
nohup command &将程序不挂起后台运行,可以部分达到守护进程效果。
系统调用和库函数
系统调用是操作系统为用户提供的接口,目的是保证操作系统的安全性。因为系统调用最终是陷入内核执行的,因此会产生内核态与用户态的上下文切换过程。Linux 下是产生 0x80 号中断,然后陷入内核执行;需要寄存器保存现场信息。系统调用一类与操作系统,可以执行相对较差。
库函数是语言或应用程序的一部分,一般在用户态执行。但是也有一些库函数的实现帅差旅是系统调用,比如 /C++ 中的 fopen, fread 调用了操作系统底层的 open, read 等等。由于库函数封装在函数库里,可移植性相对较好。
总结:
- 库函数一般在用户态执行,系统调用一般在内核态执行。
- 库函数属于过程调用,没有上下文切换,开销小;系统调用需要用户态与内核态的转换,开销大。
- 库函数封装在函数库里,可移植性较好;系统调用依赖于内核,可移植性差。
- 库函数执行时间属于 user time;系统调用则属于 system time 。
- 一般来讲库函数的数量比系统调用要多一些。
中断和异常
中断发生于 CPU 指令执行以外的事件(如设备发出的 IO 结束中断,时钟中断等)。中断使 CPU 暂停正在执行的程序,保留现场后自动转去执行相应的中断处理程序。处理完中断后再返回断点处继续执行被打断的程序。中断属于正常现象。
异常发生自 CPU 指令执行内部的事件(程序非法操作码、地址越界、算数溢出等)。对异常的处理一般依赖于当前程序的运行现场,且异常不能被屏蔽,一旦出现应当立即处理。
进程和线程
进程的概念来源于多程序并发运行的需求。操作系统最初没有多程序并发执行的概念,同一个处理机中,只有当前程序执行完毕,将 CPU 资源释放之后,另一个程序才能执行。多进程并发运行的实现,需要 CPU 时间片轮转,也即这一个时间片运行 A 程序,下一个时间片运行 B 程序。由于 CPU 运行速度极快,使得这两个程序看起来像是同时运行的,称为并发。 要做到以上需求,必然需要一种数据结构记录一个运行中的程序的现场信息,比如打开的文件描述符、程序指针、堆栈空间、程序计数器(当前执行到哪一条指令)等等,以便在释放 CPU 资源前记录现场信息、在重新获取 CPU 资源时(时间片轮转到该进程)恢复现场信息。这个数据结构就是 PCB 进程控制块,而拥有进程控制块的就是一个进程。
进程这一概念的提出,使多个程序可以并发执行,极大地提高了系统资源利用率和资源吞吐量。但是由于每个进程都拥有自己独立的内存空间,进程间隔离程度较高,也带来了多进程间通信和进程切换的开销较大的问题。为此,操作系统又引入了线程的概念。
一个进程可以由且必须由至少一个线程组成,线程是进程的实际运作单位。线程作为 CPU 调度的基本单位,只占有单独执行一个任务必需的少量私有资源(如堆栈寄存器、程序计数器等),一个进程内的所有线程共享进程的资源(内存空间等),而不是各自单独占有一片内存空间。这样一来我们可以在同一进程内创建多个线程实现并发执行多项任务,节省了进程切换的开销。具体如下:
进程间切换的内容包括 虚拟地址空间的切换(最主要) 、进程内核栈的切换、进程用户堆栈的切换和寄存器的保存。由于线程共享进程的内存空间和内核栈,因此这两个步骤线程切换时不会执行,只会保存线程的栈信息和少量的寄存器即可。因此线程间切换的开销远小于进程。
进程切换最耗时的是虚拟地址空间的切换过程,由于每个进程都有自己的独立的虚拟地址空间,把虚拟地址转换为物理地址需要通过页表(每个页表项保存了每一个虚拟地址页到物理地址页的对应)转换,但是查表转换这个过程很慢,需要 CPU 中的 TLB 缓存支持加速。既然每个进程都有自己的页表,内么进程切换时页表自然也要切换,切换完页表后 TLB 就要刷新,以前保留的内容也就是失效了,需要重新构建。
对于 Linux 而言,进程和线程没有严格的区分,其上下文信息都保存在 task_struct 结构体中(于是当然,线程也拥有自己独立的 PID 号),只是线程没有独立的虚拟内存,也即在 task_struct 中的 mm_struct 这一存储虚拟内存信息的结构体与进程内其他线程共享。
进程与线程的状态
Linux 中,线程与坚称没有严格的区分,他们都有五种状态:
- 新建态:进程刚刚被创建还没有提交操作系统的状态。在新建态,操作系统为进程创建必要的管理信息(如进程控制块等),并使进程进入就绪态。由于新建态的存在,操作系统可以根据系统性能或内存容量的限制推迟新建态进程的提交(个人理解“提交”:交由操作系统调度)。
- 就绪态:当一个进程获得了除处理机以外的一切所需资源,一旦得到处理机资源即可运行,则称此进程处于就绪状态。就绪进程可以划分为多个优先级,例如,当一个进程由于时间片用完进入就绪态,排入低优先级队列;当进程由于 IO 中断进入就绪状态,排入高优先级队列。
- 运行态:当一个进程正在处理机上占用时间片运行时,称该进程处于运行状态,出于此状态的进程的数目不超过处理器的数目,对于单处理机系统,处于运行状态的进程只有一个。
- 阻塞态:也称为等待或睡眠状态。出于此状态的进程正在等待某一事件发生(例如等待 IO 完成等)而暂时停止运行,这时即使把处理机分配给进程也无法运行,故称该进程出于阻塞状态。
- 终止态:进程已结束运行,操作系统回收除进程控制块之外的其他资源,并让其他进程从进程控制块中收集有关信息(如记账和将退出代码传递给父进程)。进程的终止也可以分两个阶段:等待操作系统善后,释放内存空间。
其中运行态到阻塞态和阻塞态到就绪态具有单向性。
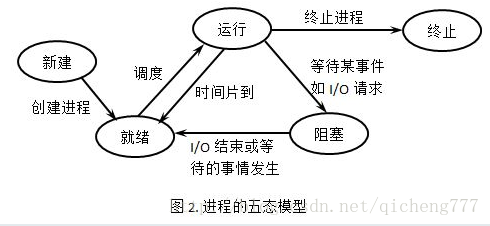
进程与线程的资源
Linux 下,只要子进程在运行过程中不对父进程的数据做修改,那么子进程基本是拷贝父进程的整个页表,共享父进程的代码段数据段堆栈段,也即他们的物理地址是完全相同的。当父进程或子进程发生写操作,才执行写时复制在写入之前拷贝出一份对应发生写操作的物理内存页 。
多线程环境下,每个线程拥有一个栈和一个程序计数器(记录下一条指令地址)。栈和程序计数器用来保存线程的执行历史和线程的执行状态,是线程的私有资源。其他资源比如 堆、地址空间、全局变量等,有同一个进程内的多个线程共享。
线程共享资源包括:
- 进程代码段。
- 进程数据段。
- 进程全局变量。
- 进程静态变量。
- 进程打开的文件描述符、信号处理器、进程当前目录和进程用户 UID、进程组 GID 等。
线程的独立资源包括:
- 线程 PID,Linux 中对线程与进程没有严格的区分,线程与进程都通过 task_struct 进行调度,于是线程也拥有自己独立的系统调度号 PID。
- 寄存器组的值,在现场上下文切换的时候用来保存和恢复现场。
- 线程栈。线程的本质是函数的执行,当开始执行一个函数,函数里可能有参数传递,可能嵌套执行其他函数,可能有函数内局部变量,这些都存储在线程栈中。
- 线程的局部存储 TLS (Thread Local Store),通过一键多值方式存储线程局部变量。
- 错误码 errno。线程若错误退出,需要返回一个特有的错误码,不能被其他线程错误干扰。
- 信号屏蔽码。
- 线程的调度优先级。
进程和线程的区别、联系
- 根本区别:进程是系统进行资源分配的基本单位,线程是任务调度和执行的基本单位。
- 开销方面:进城拥有独立的地址空间,上下文切换时需要保存和恢复页表结构,开销较大。线程自身体量小,基本上不拥有系统资源,其上下文切换的开销比进程小得多,所以以线程为调度的基本单位更能提高系统的资源利用率。
- 内存层面:操作系统为每个进程分配独立的内存空间,进程拥有独立的页表,用来存储程序所占用的资源;线程没有独立的地址空间,而是与同进程内其他线程共享地址空间。线程只拥有很小一部分内存空间用来存放一些私有数据(线程栈、进程控制块,TLS等等)
- 包含关系:一个程序至少有一个进程,一个进程至少有一个线程。
- 实现层面:进程只能由系统内核,无法从用户态实现;线程可以分为内核态线程(
clone()创建,对内核可见,由内核调度)和用户态线程(pthread_create()创建,对内和不可见,由线程库调度)。 - 通信方式:进程之间的通信需要使用管道、消息队列、信号量 等专门的进程间通信(Inter Processor Communication, IPC)方式 ,(同进程)线程间通信可以通过直接传地址或使用全局变量的方式传递变量。
多进程和多线程的区别
- 进程间数据独立,共享复杂,需要专门的进程间通信 IPC 机制;线程间数据贡献,共享简单。
- 进程的创建销毁切换开销大,速度慢;线程的创建销毁切换开销小,速度快。
- 进程占用内存多,线程占用内存少。
- 进程变成简单,线程变成复杂。
- 进程间由于空间独立,不会相互影响;线程间由于资源共享,一个线程挂掉将导致整个进程挂掉。
进程间通信 IPC 方式
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程间交换数据必须要通过内核,在内核中开辟一段缓冲区。进程 A 把数据从用户空间写入缓冲区,进程 B 再把数据从内核缓冲区读到自己的用户空间。内核提供的这种机制称为进程间通信。
进程间通信方式有:管道 pipe、命名管道 fifo,信号量 signal 、消息队列 mq、共享内存、套接字等等。
管道pipe:
也称为匿名管道,是一种半双工通信机制,数据只能单向流动且只能在具有亲缘关系(通常指父子关系)的进程间使用。 定义如下:
#include <unistd.h>
int pipe(int fd[2]);
// 充公返回 0, 失败返回 -1。fd[0] 是管道读出端,fd[1] 是写入端。
管道的实现:
- 父进程创建管道买得到两个文件描述符指向管道的两端。
- 父进程 fork 出子进程, 子进程也有两个文件描述符指向同一管道。
- 父进程关闭读出端 fd[0], 子进程关闭 写入段 fd[1]。则父进程向管道中写、子进程从管道里读。
管道的实质:
管道是一个内核缓冲区,位于内存中,进程以先进先出的方式从缓冲区存取数据,管道的一端顺序将数据写入缓冲区,另一端顺序将数据读出。
该缓冲区可看作是一个循环队列,读写的位置自动增长;数据只能被读出一次,读出后即在缓冲区消失。
当缓冲区读空或写满,读进程或写进程将阻塞并进入等待队列。当空的缓冲区有新数据写入或慢的缓冲区有数据读出,环形等待队列中的进程继续读写。
管道的局限:
- 半双工模式,只支持单向数据流。
- 没有名字,只能用在具有亲缘关系的进程之间。
- 缓存区有限。
- 传送数据是无格式字节流,这就要求管道的读出和写入必须事先约定好数据的格式,比如多少个字节算一个消息。
管道读写数据的四种特殊情况:
- 读端不读,写端一直写。当缓存区写满,write 阻塞进入等待队列,直到缓存区有数据读出。
- 写端不写,读端一直读。当缓存区读空,read 阻塞进入等待队列,直到缓存区有数据写入。
- 读端一直读,写端关闭 fd[1] 。当缓存区读空,read() 返回 0,就像读到文件尾。
- 写端一直写,读端关闭 fd[0] 。write() 子进程收到信号 SIGPIPE ,通常导致进程异常终止。
有名管道fifo
匿名管道由于没有名字只能用于有亲缘关系的进程间的通信,有名管道可以克服这一问题,定义如下:
int mkdido(const char* pathname, mode_t mode);
有名管道不同于匿名管道之处在于它提供里一个路径名与之关联,以有名管道文件的形式存在与文件系统中。这样,即使不存在亲缘关系的进程之间,也可以通过访问该路径,使用有名管道进行进程间通信。
为什么管道是半双工的
仅以匿名管道 pipe 说明。Linux 匿名管道是一个环形缓冲区,缓冲区内通过 offset 和 len 标识写入的位置和长度,发生读写的时候这些信息也会被修改。如果两个进程同时读或者写,那么势必导致读写冲突,因此内核会对管道加锁,同时只允许一个读或者写操作(互斥资源)。因此管道 pipe 只能是半双工的。
信号量
信号量本质上是一个计数器,也可以理解为一种数据操作锁,用于多进程对共享数据对象的读取。它和管道有所不同,它不以传送数据为主要目的,它主要是用来进程或线程之间的同步与互斥、保护共享资源在同一时刻只有一个进程独享。信号量有二值信号量和计数信号量,二值信号量相当于简单的互斥锁。
信号量只有两种操作:等待信号(P,表示申请一个资源)和发送信号(V,表示释放一个资源):
- P(sv),如果 sv 的值大于零,就给他减一;如果其值为零,就挂起该进程的执行。
- V(sv),如果有其他进程因为等待 sv 而被挂起,就让他恢复运行;如果没有,就使信号量 sv 加一。
临界区和临界资源:
临界资源:一次仅允许一个进程使用的资源,多个进程必须互斥地对它进行访问。
临界区:访问临界资源的代码段,每次仅允许一个进程进入临界区。
进程的互斥和同步:
互斥,指的是,当一个进程(或线程)进入临界区使用临界资源时,需要使用临界资源的其他进程必须等待。当前进程退出临界区后,需要使用该临界资源的进程解除阻塞:
P(信号量)
临界区
V(信号量)
同步,指的是多个进程的执行存在次序关系,比如 A 进程 L1 位置的执行依赖于 B 进程 L2 位置产生的数据,此时如果进程不同步,可能会发生异常。于是可以使用信号量等待 B 进程计算完成实现同步:
进程 A 进程 B
... ...
L1: P( 信号量) L2: V(信号量)
... ...
信号量和普通整型变量的区别:
信号量是非负整型变量,除了初始化之外,它只能通过两个标准原子操作:P: wait(semap), V: signal(semap) 来进行访问。
消息队列
消息队列和具名管道比较相像,都是先进先出的结构,都可以通过标识符访问。但机制则完全不一样:
消息队列总结:
- 消息队列是消息的列表,存放在内核中并由消息队列标识符标识。管道则是存在于内存(匿名管道)中或者硬盘等存储介质(具名管道)中的特殊的文件系统。
- 消息队列存在于内核中,只有当内核重启或者显式地删除一个消息队列时,才真正的消失。
- 消息队列允许一个或多个进程向他写入或读取消息,而管道则读写两端各自只能有一个进程。
- 消息队列和管道的通信数据都可以先进先出,但是消息队列可以实现消息的随机查询,也可以按照消息类型(如 pid)读取,比只能 FIFO 的管道更有优势。
- 消息队列中的数据具有特定格式,管道则只能承载无格式字节流的管道。
- 目前主要用两种类型的消息队列:POSIX 消息队列和 System V 消息队列,后者被大量使用,且是随内核持续的,只有在内核重启或者人工删除时才会被删除。
- 消息队列在某个进程向其写入数据时,并不需要另外某个进程在该队列上等待消息到达,而管道若写入端持续写,读出端关闭的情况则报错误。
共享内存
消息队列和管道都是系统调用,需要陷入内核空间,数据从 A 进程到 B 进程一共需要两次上下文切换和四次拷贝:
- A 进程用户空间到 A 进程内核缓存区 –>
- A 进程内核缓存区到内存 –>
- 内存到 B 进程内核缓存区 –>
- B 进程内核缓存区到 B 进程用户空间
共享内存机制预留出一段专用的内存区,可以由需要访问它的进程将其映射到自己的虚拟内存空间,并且允许多个进程共享这一段内存。这一段内存可以用作专门的进程间数据交换空间,这样一来,数据从进程 A 到进程 B 的拷贝次数就缩减到了两次:
- A 进程用户空间拷贝到共享内存空间 –>
- 共享内存空间拷贝到 B 进程用户空间
共享内存允许多个进程可以读写同一块内存空间,是最快可用的进程间通信 IPC 形式。但是也由于多个内存共享同一片内存,因此需要依靠某种同步机制(如信号量)实现进程间同步及互斥。
共享内存可以通过 mmap() 系统调用实现,也有其他方法,没有仔细钻研。
临界资源和临界区,同步和互斥
总结一下:
- 临界资源是同时只允许一个进程或线程访问的资源。
- 临界区是访问临界资源的那段程序。
- 互斥指的是对共享资源保证同一时刻只有一个进程或线程访问,具有唯一性和排他性,但是无法保证对资源访问的有序性。
- 同步指对资源的有序访问,多个线程彼此合作,通过一定的逻辑关系来共同完成一个任务;同步建立在互斥的基础上。
僵尸进程、孤儿进程及其回收
- 僵尸进程:子进程先于父进程结束,但是父进程没有调用 wait 或者 waitpid 回收子进程的 PCB,那么子进程成为僵尸进程。大量的僵尸进程会一直占用系统的资源。
僵尸进程的回收,可以杀死其父进程,由 innit 接管进程,完成资源的释放。但更好的办法还是通过其父进程主动调用 wait() 或 waitpid() 方法回收。 - 孤儿进程:父进程先于子进程结束,子进程成为孤儿进程,由 init 进程接管。init 负责孤儿进程的回收。
子进程的回收:
一个进程在终止时会关闭所有文件描述符,释放在用户空间分配的内存,但它的 PCB 还保留着,内核在其中保存了一些信息:如果时正常终止则保存退出状态,如果时异常终止则保留着导致进程终止的信号。这个进程的父进程可以调用 wait 或 waitpid 获取这些信息,然后彻底清除这些进程。
c++ 的内存分配,堆和栈
堆栈是数据结构中的叫法,代表两种不同的数据结构;内存模型中的相应表达是,堆区和栈区,代表两种不同的内存分配方式。
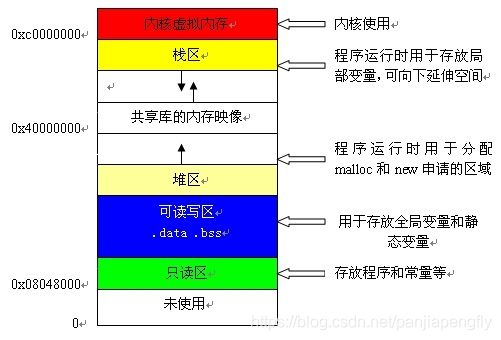
C/C++ 的内存模型分为五个区:堆区、栈区、静态区、常量区、代码区。其中:
- 代码区存放代码,只读。
- 常量区存放常量,只读。
- 静态区存放全局变量和静态变量,初始化的全局和静态变量存储在一块区域,未初始化的全局和静态变量存储在另一块区域。
- 堆区是程序员通过
new/malloc手动分配,通过free/delete手动释放的存储区。堆区的分配方式类似于数据结构中的链表,如果程序员没有主动回收,会发生内存泄漏(程序生命周期内无法再次使用这片内存);未被主动释放的堆区资源会在程序结束时被操作系统回收。堆内存的分配 - 栈区存放函数的参数值、局部变量等,由编译器自动分配和释放,通常在函数执行完毕即刻释放,其分配方式类似于数据结构中的栈。栈内存的分配内置于 CPU 指令集,效率高,但分配的内存量有上限且较小。
内存模型中堆区栈区的对比
- 申请方式
栈区:由编译器自动分配释放,存放函数的参数值和局部变量等。
堆区:程序员使用new/malloc等语句主动申请,使用free/delete等语句主动释放。若没有主动释放,在程序结束时被操作系统回收;且会发生内存泄漏。 - 分配方式
栈区:类似于数据结构中的栈,先入先出,内置于 CPU 指令集。
堆区:类似于数据结构中的链表。 - 申请后系统的响应
栈区:只要栈内剩余空间大于所申请空间,系统将为程序提供内存,否则报异常提示栈溢出。例如 c++ 中通过int a[len];方式建立一个很长的数组,如果 len 很大以至于数组其长度超出了栈所能提供的内存,程序即报“栈溢出”异常;超长数组可以通过int *a = new int(len);主动申请堆内存方式获取。
堆区:操作系统维护一个记录空闲内存地址的链表,当系统收到申请,会遍历该链表。找到第一个空间大于申请空间的堆结点,将此节点从空闲结点链表中删除,并将该节点的内存分配给程序。大多数情况下,找到的对接点大小不一定正好等于申请的大小,操作系统后自动将多余的那一部分重新放回到空闲地址链表中。另外,操作系统会在这块内存空间的首地址记录本次分配的大小,这样调用free/delete语句时才能正确释放这一片内存空间。 - 内存区大小和内存表现
栈区:栈区是一块连续的内存区域,这句话的意思是栈的最大容量是操作系统预先规定好的。在 linux 系统中一般是 8M 或 10M,根据发行版不同而不同。可以通过ulimit -s指令查看,ubuntu1804LTS 发行版上是 8192 (单位KB),也即 8M。
堆区:由于操作系统使用链表存储空闲内存空间,分配给程序的堆区空间自然是不连续的。也由于堆区空间的分配是遍历链表分配空闲内存空间,其容量是没有限制的,或者说只受限于操作系统有效的虚拟内存。 - 申请效率
栈区:操作系统分配连续的内存空间,速度快。
堆区:程序员主动申请,遍历空闲地址链表寻找可分配空间,速度慢。 - 存储内容
栈区:第一个进栈的是主函数(调用该函数的函数)中的函数调用语句的下一条可执行语句的地址,然后是函数的各个参数,函数中的局部变量。静态变量不入栈。
堆区:堆的头部使用一个字节存储堆的大小,堆中具体内容由程序员安排。
进程调度算法
进程调度发生在以下四种情况:
- 进程从运行状态转到等待状态
- 进程从运行状态转到就绪状态
- 进程从等待状态转到就绪状态
- 进程从运行状态转到终止状态
其中从运行态转到等待或就绪两种状态的调度是非抢占式调度,从运行或等待转到就绪状态的调度是抢占式调度。
非抢占式调度指的是,当进程正在运行,他会一直运行,直到该进程完成或者被阻塞时,它才将 CPU 资源让渡给其他进程。
抢占式调度指的是,进程在运行时,可以被打断,使其将 CPU 资源让渡给其他进程。
- 先来先服务 First Come Forst Severd, FCFS
先来先服务是一种非抢占式调度算法,是最简单的调度算法。该调度算法每次从就绪队列里选择最先进入队列的进程进入运行态,然后一直运行直到进程退出或者被阻塞,才允许下一个队头(最先进入队列)就绪任务进入运行态。
这种调度算法对长作业有利,对短作业不利。当一个长作业先运行了,后面的短作业等待的时间就会延长。
- 最短作业优先 Shortest Job First, SJF
最短作业优先是一种非抢占式调度策略,它使队列里执行时间最短的作业优先运行,如果多个作业的执行时间相同,则按照先来先服务调度。显然 SJF 是一种贪心算法。SJF 有助于提高系统吞吐量,但对长作业不利。当就绪队列里短作业较多或者不断有新的短作业插入时,长作业久久得不到执行,容易造成长作业饥饿。
- 最短剩余时间优先 Shortest Remaining Time First, SRTF
最短剩余时间有限是最短作业优先 SJF 的抢占式版本。在 SRTF 中,进程可以在执行一段事件后被暂停。每个新作业到来时,短期调度程序在可用进程列表和正在运行的进程中以最少的剩余突发时间 安排进程,也即,在突发时间这一指标上,谁最靠前(剩余最少),就把谁排在前面。
- 最高响应比优先 Highest Response Ratio First, HRRF
高响应比优先算法综合了了短作业优先和先来先服务的特性,也能兼顾到长作业。HRRF 对每个任务计算一个优先权,优先权=(等待时间+要求服务时间)/要求服务时间,由于 (等待时间+要求服务时间)= 响应时间,故名高响应比优先。为什么说该算法综合了短作业优先和先来先服务特性的同时又能兼顾到长作业:
对短作业优先,在等待事件相等的情况下,显然要求作业时间越短,该优先级越高。
对先来先服务,当作业时间相等,显然先来的任务等待时间更长,则其优先级更高。
对长作业,和先来先服务类似,一个长作业等待的时间越长,期优先级越高。
- 时间片轮转 Round Robin, RR
这个比较容易理解,是最公平最简单的一种调度算法。所有到来的进程会被分配一个时间片,只允许在该时间片内运行,按照到达的先后顺序运行。时间片内运行结束或阻塞,则 CPU 立即切换,进入下一个进程时间片(若结束,则移出队列);否则时间片用完,进程被释放为等待状态,让渡出 CPU 资源,进入下一个进程时间片。
时间片的长度通常在 20~50 毫秒,太短会导致频繁的上下文切换,降低 CPU 效率;太长则段作业响应时间变长。
- 最高优先级 Highest Priority First, HPF
最高优先级调度算法认为任务存在优先级,希望从就绪队列中选择具有最高优先级的任务优先运行。任务的优先级可以分为静态优先级和动态优先级。静态优先级在进程创建的时候就已经确定,整个运行期间都不会改变;动态优先级则会随进程的动态变化而改变,比如如果进程运行时间增加,则降低其优先级,等待时间增加则增大优先级。有点像高响应比优先 HRRF。
HRRF 也分为抢占式和非抢占式。非抢占式是,当就绪队列中出现优先级高的进程,运行完当前进程再选择优先级高的进程;抢占式是,当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。