yolov5还是有一些有意思的东西的,做一个简单的解析,给自己看。
概述
先放一张网络图镇宅。
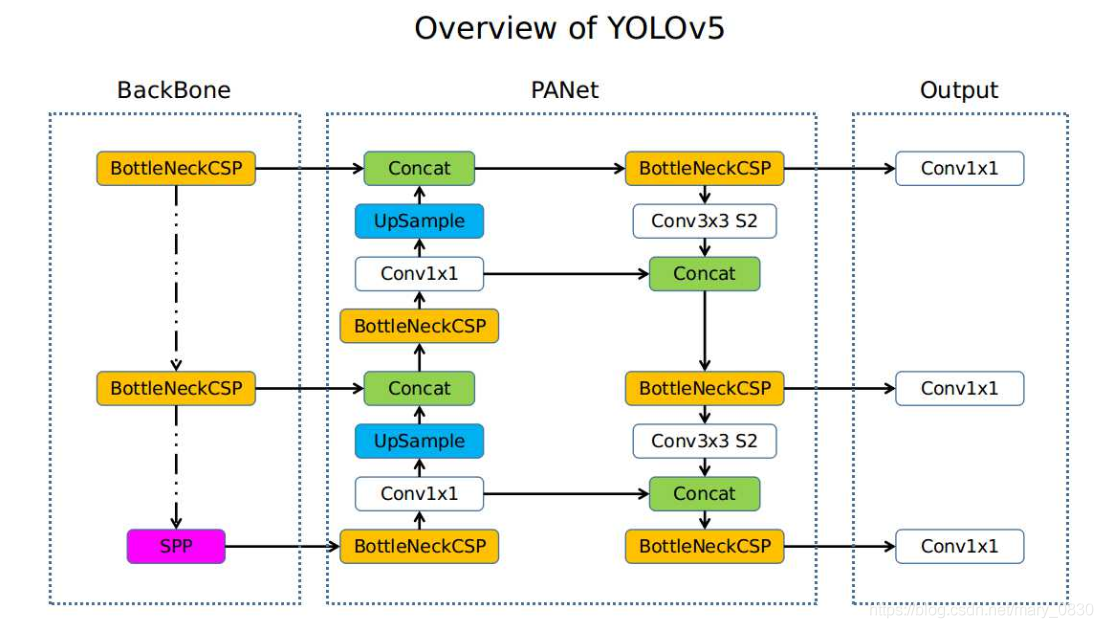
图中 BackBone 阶段主要包括 Focus, Conv, BottleneckCSP, SPP 等几个模块, Head 阶段主要包括 BottleneckCSP, Conv, nn.Upsample, Concat, nn.Conv2d, Detect 等几个模块。其中 nn.xxx 来自 torch.nn, 是 pytorch 的原生模块,其他的则在 models/commons.py 文件中定义。
models/commons.py 中还定义了许多其他模块,可能是别的地方用的吧?一并进行解析。下面按照 models/commons.py 中的顺序一个个儿来。
目录
给个目录,万一有人看呢。
- Mish
- Conv
- BottleneckCSP
- BottleneckCSP2
- VoVSP
- SPP
- SPPCSP
- MP
- Focus
- Concat
- NMS
- autoShape (略过)
- Flatten (略过)
- Classify
- Detect
Mish
class Mish(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * torch.tanh( F.softplus(x))
return x
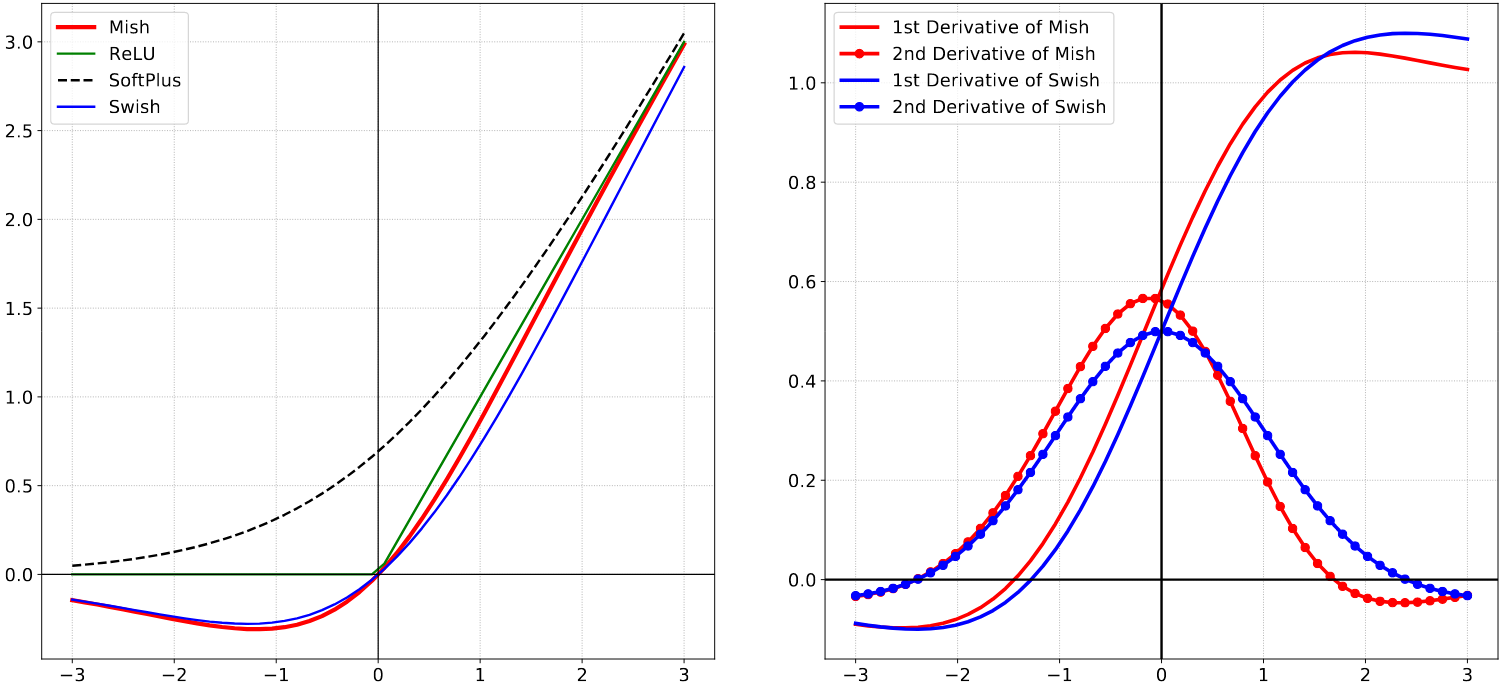
Mish 是 yolov5 中 BottleneckCSP 和 BottleneckSSP 使用的激活函数,注意,常规卷积 Conv 模块没有使用 Mish。该激活函数出自论文Mish: A Self Regularized Non-Monotonic Activation Function,由 softplus 和双曲正切 tanh 组成:$Mish(x) = tanh( softplus(x))$ 。回顾一下双曲正切 tanh 的定义:
$tanh(x) = \frac{sinh(x)}{cosh(x)} = \frac{e^x - e^{-x}}{e^x + e^{-x}},$
$\ \ \ sinh(x) = \frac{e^x - e^{-x}}{2}, \ \ \ \ cosh(x) = \frac{e^x + e^{-x}}{2}$
github page 中双美元符号 $$ 包裹的公式块无法渲染,只能用单美元符号 $ 包裹的行内公式凑活一下,就是不太好看。
tanh关于原点对称,其值限定在 [-1, 1] 范围,且在一定范围内接近线性变换。
softplus 是一种由指对数函数组成的激活函数: $softplus(x)=log(1+e^x)$ ,其大于零的部分斜率接近 1 ,小于零的部分值向 0 逼近,近似 ReLU 却十分光滑。值得注意的是,在 pytorch 的实现 中,额外给了该函数一个参数 $\beta$ ,公式就变成了:$softplus(x)=\frac{1}{\beta}log(1+e^{\beta\cdot x})$。但是,该参数默认是 1。
论文中给出的 Mish 及其他各相关函数曲线和一二阶导数曲线如下图,
Conv
# Standard convolution
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
# ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
代码来看,yolov5 中定义的 Conv 类就是 nn.Conv2d( [argvs ...]) 类的简单封装。默认使用 bn 层,当然,注意 bn 层的参数是 c2 = channel_output 。通过 bool 类型参数 act 确定是否使用激活层,当期值为 act = False ,使用 nn.Indentity() 做激活函数,也即不激活;如果其值为默认值 act = True ,则激活函数为 nn.Hardswich():
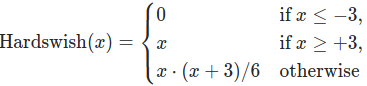
破东西。根据pytorch Documents,该激活函数出自 MobileNetV3,臭名昭著的负优化网络。怪不得使用原生yolov5跑检测的时候结果总是不尽人意。这里,使用的时候要改,改成经过时间检验的激活函数,ReLU, LeakyReLU, Mish之类的。
Conv 默认的卷积核是 1 ,yaml 文件中调用 Conv 模块时指定了 k=3, 也即使用常规的 $3\times 3$卷积。指定了分组卷积参数 $g$ ,但其默认参数为 $g=1$ ,反正就是不分组;当然,可以自己另行指定 $g$ 参数改为使用分组卷积;common.py中也另外实现了 Depthwise Convolution 函数。由于 pytorch 原生的 nn.Conv2d() 卷积无法通过 padding=same 这一类的参数指定 padding 值(见 pytorch 官方文档),Conv 使用了自定义函数 autopad(k, p=None) 指定 padding 值。
common.py 中还基于 Conv 实现了 DepthWise Convolution ,但不知道在哪儿使用的。
autopad
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
用来实现 nn.Conv2d 中 padding=same 的函数。由 $d_{out}=\frac{d_{in} + 2p - k}{s}$ ,当指定 $p=\frac{k}{2}$ 时,特征图尺寸是否折半则完全取决于步长参数。各网络yaml 文件中 yolov5 系列网络通常使用 Conv 实现下采样功能,于是可见各 yaml 文件中都指定 Conv 的步长为 2(此处指向对yolov5的模型解读博客)。由于卷积核长度 $k$ 通常是奇数,而 python 中的 / 操作处理两个整数之间的除法时会产生浮点数,从而使用 // 操作符将除法结果向下取整。
此外该函数对原始给定的卷积核长宽值 k 进行了一次是否为整型的类型判断 isinstance(k, int),当其非整型则以列表形式返回相应的值。这是由于虽然极其罕见,但 kernel 的长宽是被允许不一致的。然而,在什么情况下才会用到长宽不一致的 kernel ,反正我是没遇到过。最后但是,根据 pytorch Documents 中有关 Conv2d 模块的源码及注释,k 参数可接受的值是 int 或 tuple, 返回一个列表是什么意思?
DWConv
def DWConv(c1, c2, k=1, s=1, act=True):
# Depthwise convolution
return Conv(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
由 MobileNetV1,当分组卷积的分组数量等于输入卷积核的通道数,也即 g = c_in 使得每个卷积核的尺寸变为 $1\times K\times K$,此时的分组卷积称作 DepthWise Convolution。yolov5上的这个实现,应当是考虑到更一般的情况:满足 g = c_in 的 g 是否能同时满足 $\frac{c_out}{g}\in N^*$。为避免分组数不能被输出通道数整除的情况发生,采取一种折中的方法:取输入输出通道的最大公约数作为分组数 $g = gcd(c_in, c_out)$。但是这样是否还能叫做 DepthWise Convolution,暂且存疑吧。
Bottleneck
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
# ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
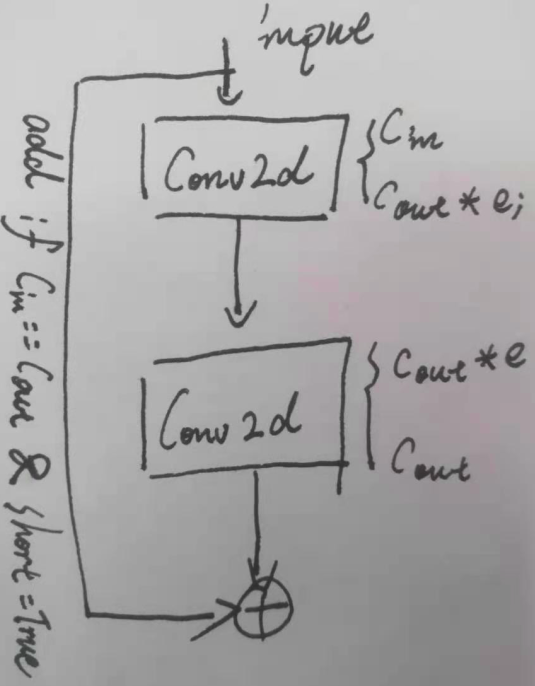
Bottleneck 模块应该也是出自 MobileNetV2,由有两个 Conv 卷积和一个 shortcut 组成。其中第一个卷积为 $1 \times 1$ 卷积,并通过一个 expansion 参数(通常是小于 1 的)减少特征图通道数。后面一个正常的 $3\times 3$ 卷积恢复特征图通道数至原来(或其他指定的)水平。若此时输出的特征通道数与输入到该模块的原始特征通道数量相同,c_in = c_out,则可以通过一个 shortcut 结构进行残差连接。其架构如下图,由于中间一层特征图通道数往往小于输入输出层,一些解读中称之为“沙漏型”结构。
BottleneckCSP
class BottleneckCSP(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
# ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = Mish()
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
该结构中的 CSP 全称是 Cross Stage Partial 出自论文CSPNet。其结构大致是正常的卷积或其他模块外面再加一个并行的卷积,两个支路的输出 concat 后再通过(通常是)卷积融合特征。论文原文中以ResNet为例给出了示意图如下:
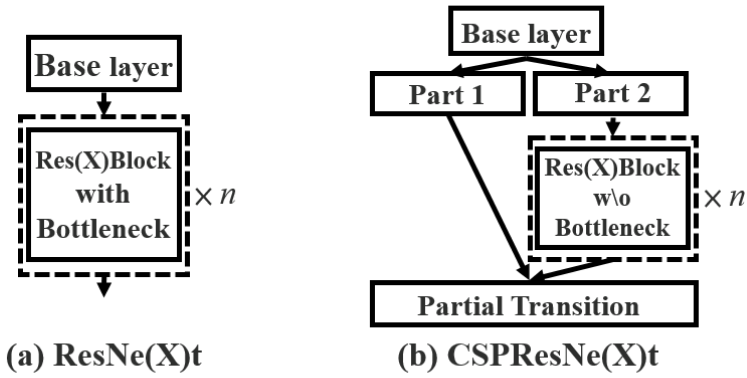
BottleneckCSP 则相应的是将上图中 Residual block 残差块结构替换为上一部分介绍的 Bottleneck 结构。其整体结构如下图:
这里应该还要注意,虽然 BottleneckCSP 模块构建 Bottleneck 的时候使用 for _ in n 的语句进行重复构建,但通常,使用默认值 n = 1。且 yaml 文件中的 args 参数跟这里的 n
没有关系,当时我误以为是 n ,实际上 args 参数应该是输出通道数 c2。而输入通道数则自动解析为上一层的输出。
cat 也要注意,为什么在 dim=1 维度上进行 cat? 一张特征图的通道维度,直觉应该是 0 或 2,此处不细究,记下吧。
BottleneckCSP2
class BottleneckCSP2(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
# ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP2, self).__init__()
c_ = int(c2) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv3 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_)
self.act = Mish()
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
x1 = self.cv1(x)
y1 = self.m(x1)
y2 = self.cv2(x1)
return self.cv3(self.act(self.bn(torch.cat((y1, y2), dim=1))))
也是一个CSP结构。CSP还是比较灵活的,只要符合外层再加一并行的卷积分支都可以叫做CSP。这个结构相比于上一个 BottleneckCSP,相对矮胖,画一下他的结构图如下:
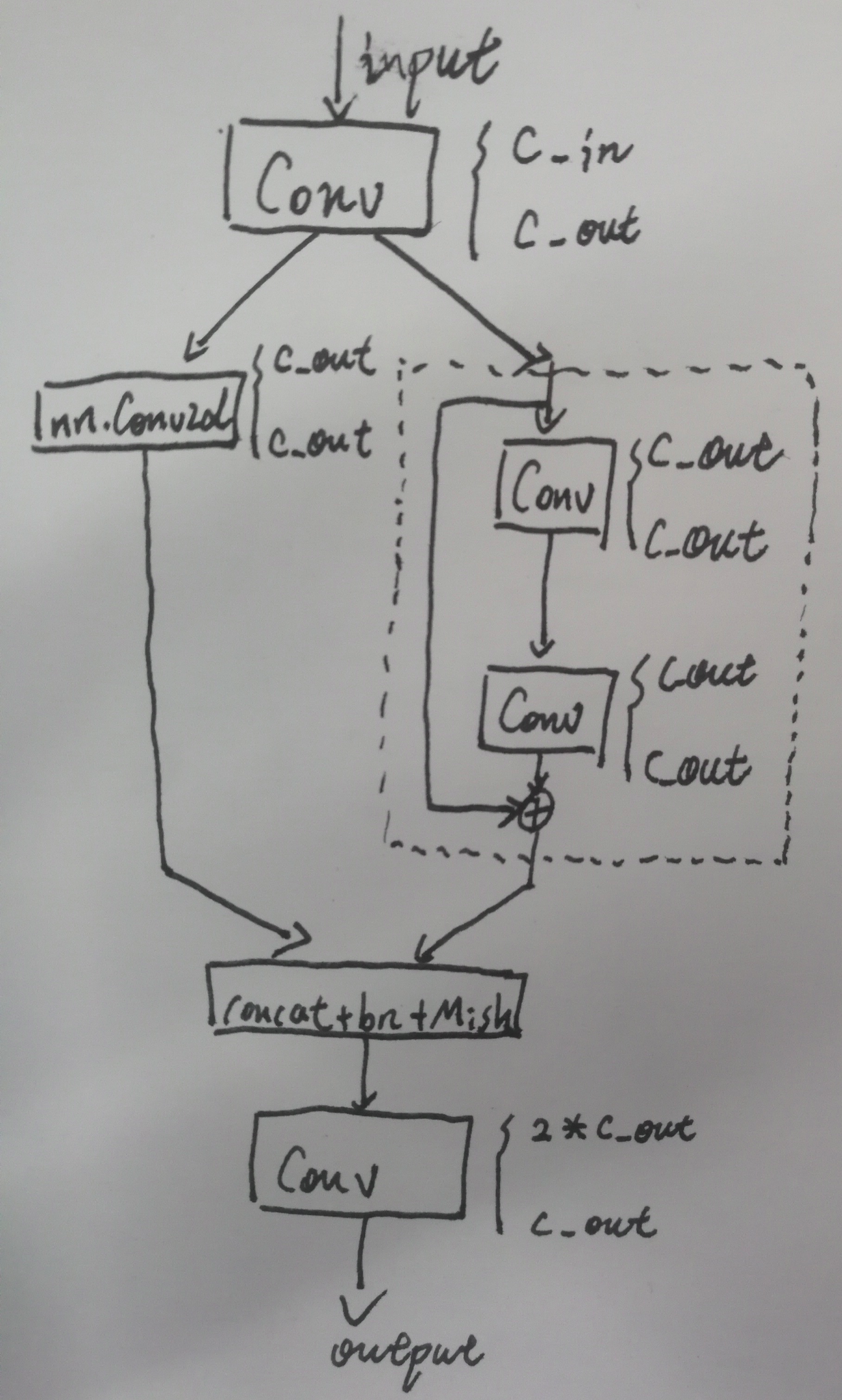
由代码和结构图可以看出,这个 BottleneckCSP2 相比上一个 BottleneckCSP 主干网络少了上下两个 Conv 模块,又在分支前先做了一次 Conv 。且由于模块一开始就设定了 c_ = c2 ,整个BottleneckCSP结构中隐层特征图通道数没有减少,在完成分支合并的 concat 操作后特征图通道数变成了 2×c_,随后的最后一个 Conv 操作才又使特征通道数降回到 c_ = c2。 从而,描述其为一个相对矮胖的 BottleneckCSP 模块。
VoVCSP
class VoVCSP(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
# ch_in, ch_out, number, shortcut, groups, expansion
super(VoVCSP, self).__init__()
c_ = int(c2) # hidden channels
self.cv1 = Conv(c1//2, c_//2, 3, 1)
self.cv2 = Conv(c_//2, c_//2, 3, 1)
self.cv3 = Conv(c_, c2, 1, 1)
def forward(self, x):
_, x1 = x.chunk(2, dim=1)
x1 = self.cv1(x1)
x2 = self.cv2(x1)
return self.cv3(torch.cat((x1,x2), dim=1))
这个模块是真的迷。
首先看 forward 前向传播,chunk(torch的反 cat 操作)分割后,两个并行的卷积分支竟然是一样的,那剩下的一半特征就直接不要了吗?
随后看两个并行的卷积分支自身, cv1 和 cv2 ,输入通道数竟然不一样,一个 c1//2 ,一个 c_(=c2)//2 ,虽然,我们知道通常情况下有 c1 = c2 ,但,你这样定义,过分了吧。
好在,没找到这个模块在哪儿用到,应该是没有实际使用。
SPP
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
空间金字塔池化操作,出自何凯明2014年的工作Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,此处的使用意图和原作中解决图片尺寸不一而导致最终全连接层长度不一的意图不一样。用法相似但也不一样。此处是使用不同尺寸的 pooling 结合各尺寸相应的 padding 得到新的相同尺寸特征图,与原特征图 concat 后进行其他处理。当然,此处的实现同样在 pooling 前后封装了 Conv 模块。更形象一点儿的,看下图吧。
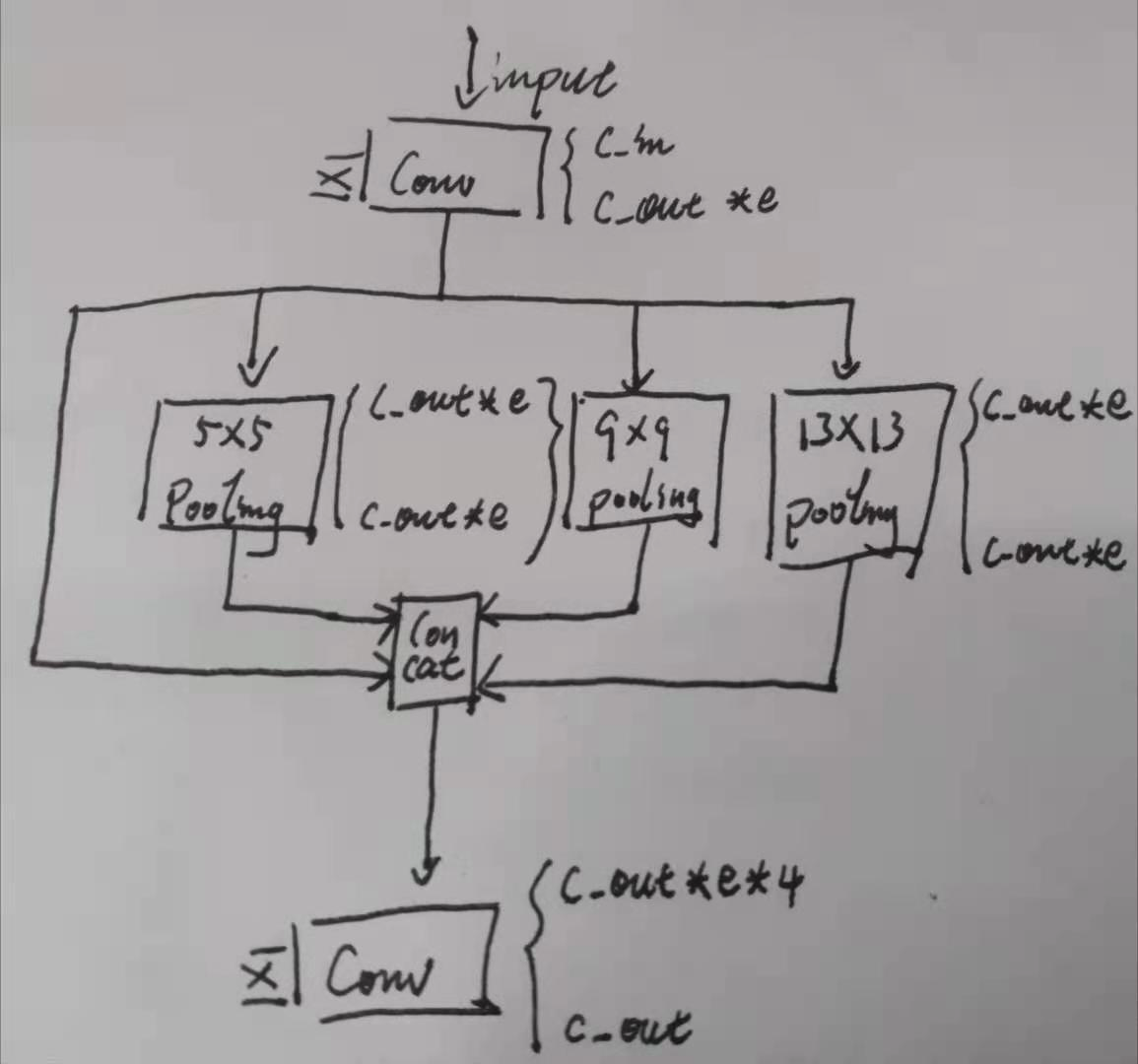
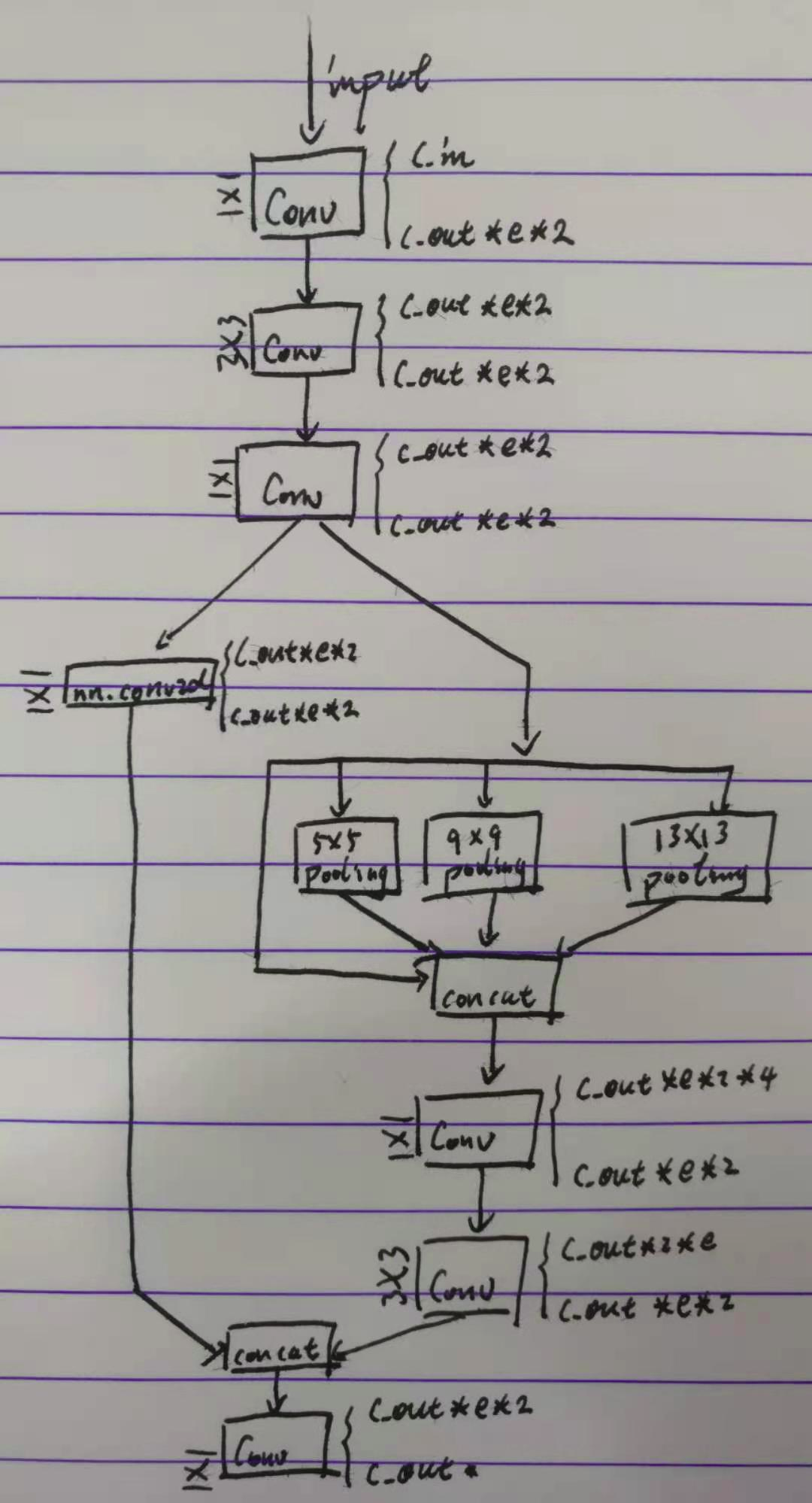
SPPCSP
class SPPCSP(nn.Module):
# CSP SPP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSP, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.bn = nn.BatchNorm2d(2 * c_)
self.act = Mish()
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(self.act(self.bn(torch.cat((y1, y2), dim=1))))
看得出来作者挺喜欢用 CSP 结构的, 一个池化操作都能上CSP。 同样也没什么好说的,直接看图。
MP
class MP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, k=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)
def forward(self, x):
return self.m(x)
默认 k=2, s=2 的最大池化,没什么说的。
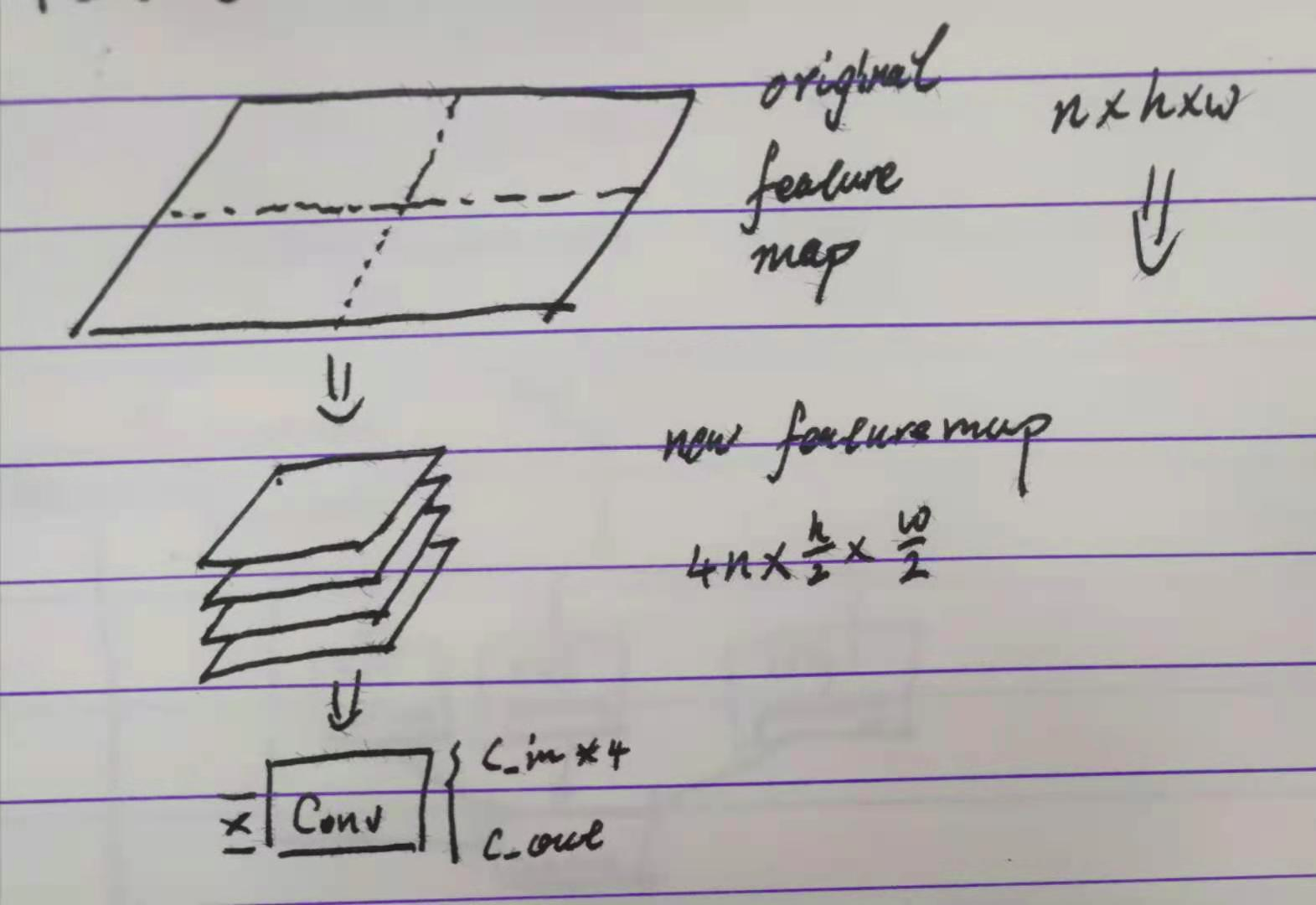
Focus
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
# ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
这东西就好玩儿了。Focus 的本意其实是将一张特征图(通常是整个网络的输入)四等分后再摞起来,从而减少后续的卷积计算量,实际上它也做到了。但唯一疑惑的地方,按照代码来看,进行切分的是特征图的后两个维度,也即第 0 维应当确认是 channel 维度,可是最后进行 concat 的时候依然在 dim = 1 维度。这样的话,四个[n, w, h] 的张量 concat 后不就成了 [n, 4w, h] 了吗? 破东西,很迷。但思想是比较好的:
Concat
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
没什么说的,就是把 torch.cat 做个指定 dim=1 的封装。这个 dim = 1,我靠,什么屁东西。你的 channel 维到底是0还是1?莫非送入网络计算的时候 batch 算单独的一个维度?
NMS
class NMS(nn.Module):
# Non-Maximum Suppression (NMS) module
conf = 0.25 # confidence threshold
iou = 0.45 # IoU threshold
classes = None # (optional list) filter by class
def __init__(self):
super(NMS, self).__init__()
def forward(self, x):
return non_max_suppression(x[0], conf_thres=self.conf, iou_thres=self.iou, classes=self.classes)
也没什么说的,就是把 utils.general 中的 non_max_suppression 做个封装。但是没见哪儿用了这个模块,在 train.py ,test.py ,和 detect.py 中都是直接调用了 non_max_suppresion 模块。
Flatten
class Flatten(nn.Module):
# Use after nn.AdaptiveAvgPool2d(1) to remove last 2 dimensions
@staticmethod
def forward(x):
return x.view(x.size(0), -1)
很简单的一个Flatten,对 pytorch 原生的 view() 函数进行了封装。值得注意的地方有三点:
- 该类的前馈方法 forward 被修饰伪静态方法,可以直接
Flatten(xxx)调用而无需实例化类为具体对象。 - 需要先
nn.AdaptiveAvgPool2d(1)使特征图张量的长款尺寸将为 1 。 - 只是一个Flatten,没有全连接运算。
Classify
class Classify(nn.Module):
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1):
# ch_in, ch_out, kernel, stride, padding, groups
super(Classify, self).__init__()
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) # to x(b,c2,1,1)
self.flat = Flatten()
def forward(self, x):
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
return self.flat(self.conv(z)) # flatten to x(b,c2)
分类层。
z = xxxxx 这一行很有意思,有意思主要在对输入 x 的类型做了一次判断,判断其是否是 list 类型。事实上,x 应当是输入到 Classify 层的特征图,那么无论是否有 Batch 这一维度,它都应当是完纯的 tensor 类型嘛,怎么可能是 list 呢?
虽然,判断语句写的是如果不是 list 则强行 [x] 转换为 list。然后在channel维度 concat,你这,concat 了个寂寞吗?
还是说,强行转 list 这个过程是将 tensor 的 batch 维度转成了 list 的 item ?
我试了一下,也不是啊,强行 list 只是在 tensor 的最外面裹了一层 [] 而已嘛。有点儿迷。
随后 $1\times 1$ 卷积改变一下维度接 Flatten 展平。
但你一个分类层,不封装 activation ,过分了吧?
Detect
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape
# x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
出现在 yaml 文件的检测网络的最后一层的检测层。
最开始两个变量不用管,export 还是要注意一下的。
这个yolov5整的挺人性化,可以很方便地转成 onnx 。转 onnx 的时候需要用到 export.py 这个文件,和此处的 export 有关,但这个值得具体含义可以暂且不论。
从 __init__ 开始一行行地看。
开始一堆 self.xx 指定原始诸参:
self.nc = nc,指定检测的类别数,有多少就是多少。self.no = nc + 5,指定每个 anchor 的输出元素数量。一般就是 n+5 ,n 是针对每个类别的 softmax 输出,5 包括了四个定位元素(中心点及宽高)和一个置信度 conf。self.nl = len(anchors),检测层数量,对应的是 yaml 文件里有几行 anchors 。按照这里的写法,应当是将 anchors 解析为一个二维列表。self.na = len(anchors[0] // 2), 注释上写的是 “ number of anchors ”,但这个意思是,每个检测层的 anchors 数量?self.grid = [torch.zeros(1)] * self.nl,注释写的是 “ init grid ” 初始化检测网格。啥意思?
有点儿费脑子,时间不够了,先留着,有时间了回头再更新