2020年首届智能船舶检测挑战赛使用yolov5获得研究生组三等奖,简单记一些目标检测任务的小知识和比赛tricks。
首先指出框架相关的问题
我们使用了u版yolov5,改变网络结构比较方便。但即使自己改了更大的backbone,对数据进行了细致的清洗和花式的加噪曾广,对网络本身和检测方法竭尽所能添加tricks,最后也只是三等奖的水平。坤乾老师的学生原封不动使用scaled-yolov4,达到了一等奖的水平。这里对yolov5的实际效果表示严重怀疑。
后来的一次水下目标检测任务,我测试了scaled-yolov4,效果的确比yolov5优秀。但也发现针对简单任务,大模型的效果反而不如较小模型,甚至超大模型还会出现loss报NaN的问题。
比赛实录
数据集
所谓数据比赛,一半以上的成绩在于数据集的处理。
voc转yolo(小目标清洗)
简单来说,VOC的xml格式图像和bbox尺寸是整数,该多大是多大,bbox通过角点坐标确定;yolo的规则中,bbox的长宽相对于图像长宽归一化到1.0以内,位置和尺寸通过中心点集宽高确定。转化的代码网上一找一大堆,但实际操作还是要结合任务的具体情况。最核心的部分就两个函数:
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
if x>=1:
x=0.999
if y>=1:
y=0.999
if w>=1:
w=0.999
if h>=1:
h=0.999
return (x,y,w,h)
def convert_annotation(rootpath, xmlname):
xmlpath = rootpath + '/xmls'
xmlfile = os.path.join(xmlpath,xmlname)
with open(xmlfile, "r", encoding='UTF-8') as in_file:
txtname = xmlname[:-4]+'.txt'
print(txtname)
txtpath = rootpath + '/labels' #生成的.txt文件会被保存在labels目录下
if not os.path.exists(txtpath):
os.makedirs(txtpath)
txtfile = os.path.join(txtpath,txtname)
with open(txtfile, "w+" ,encoding='UTF-8') as out_file:
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
out_file.truncate()
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes:
# if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), \
float(xmlbox.find('xmax').text), \
float(xmlbox.find('ymin').text), \
float(xmlbox.find('ymax').text))
objWidth = b[1]-b[0]
objHeight = b[3]-b[2]
if objWidth > w or objHeight > h or objWidth*objHeight<=21:
continue
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) \
for a in bb]) + '\n')
这东西就是轮子,轮子怎么造的不做解读了,主要是会用。指出几个需要注意的点:
txtpath = rootpath + '/labels'这一行,labels路径需要自己事先创建,不会自动创建。difficult = obj.find('difficult').text这一句;比赛数据集没有difficult项,事实上,我遇到的大多数数据集都没有这一项,直接注释掉即可。- 相应地,后面条件语句里面的
int(difficult)==1这一判断也得删掉,只留一个if cls not in classes。 - 有些数据集,比如这次比赛用的数据集,标注是有问题的。存在很多误标的 ground truth,猜测是标注数据的学生手一抖,就点了俩点儿,成了一个 ground truth。这种情况可以在读 xml 文件的时候通过
bbox和weight/hight把长宽/像素值或其相对整体图像的比例小于某个值的目标筛掉,不进入转yolo的过程。
具体的实现上,如果已有的VOC数据集本身已经分好组了(在数据比赛中,这应该是大多数情况),则遍历train和a_test路径调用函数即可。
数据集划分
考虑一般情况下,数据比赛给出的a_test只是用来打榜,自己还是需要另外分一个val验证集用以在训练过程中监控网络状态。下面给出已将数据按yolo要求组织后,划分数据集的代码。
valImg = "xxx" # 将要被划分出来的验证集图片路径
trainImg = "xxx" # 目前图片路径
valLabel = "xxx" # 将要被划分出来的验证集标签路径
trainLabel = "xxx" # 当前标签路径
files = os.listdir(trainImg)
for f in files:
if random.random()<0.25: # 这个比例按需求来
shutil.move(trainImg+f, valImg+f)
shutil.move(trainLabel+f.replace('jpg', 'txt'),
valLabel+f.replace('jpg', 'txt'))
负样本和空标签
比赛中去除了所有空标签,因为我们认为数据足够多、样本足够丰富,负样本的存在没有必要。但另一项简单的水下目标检测的任务中,由于目标和场景过于简单,且有些背景和目标过与相似,则需要添加相应的负样本。所谓负样本,就是对应于某图片的标签文件存在但为空。
删除空标签
通过python读文件操作判断文件是否为空,遍历标签文件直接删除空标签文件。参照Python实录01。
添加负样本
如果是自己收集的图片,则遍历没有标签的背景图片,并通过系统命令 touch 生成相应的空标签:
files = os.listdir("./background/")
for f in files:
label = f.replace("jpg", "txt")
os.system("touch trainLabel/" + label)
需要注意的是,执行这一步的时候应该先行筛选出一定数量和形式的负样本图片,并加入到数据集。
添加噪声
给清洗完毕的数据添加噪声是一种非常有效的涨点方法。比赛总共使用了三种噪声和两种添加方式,为原图片添加了五类噪声,简单介绍如下:
三种噪声:
- 椒盐噪声:由 0(0.0) 和 255(1.0) 两个值组成的噪声。噪点在彩色RGB三通道图像中的位置可以相同,也可以不同。
- 高斯噪声:符合高斯分布的噪声。
- 叠加噪声:将另一幅图片的(部分)像素值按一定比例和权重叠加到目标图片。
两种添加方式:
- 像素相加:全部噪声像素和输入图片按不同权重直接相加,超过255的部分直接砍掉。
- 像素替换:按一定的比例将原始图片中部分像素直接替换为噪声像素。
添加噪声的代码如github/smartShip2020/data/dataReformance.py所示。需要注意的一个点儿是,添加噪声对时间序列没有要求,可以调用python多进程工具进行并行处理,配合numba加速工具,可以极大地加快处理速度。
数据集布置和yaml指向
划分好的数据集应当保持图片和label名称对应,且应当分开放置。数据集可以,并且也建议和代码分开放置。比如一般地,代码应当在/home路径所在的ssd盘,而数据集应当放置在/data所在的机械盘。
在/path/of/data路径下分别建立images/和labels/子路径( 必须要遵循这个名称 )用于存放图片和标签文件,两个子路径再分别建立对应的train/, val/等次级子路径,用于存放训练集和验证集。
跑train.py的时候,有个需要指定的超参数--data。该参数指向的是一个yaml文件,文件里写明了数据及的分布和组织:
train: ./data/images/train/
val: ./data/images/test_a/
test: ./data/images/test_b/
# number of classes
nc: 6
# class names
names: ['liner', 'container ship', 'bulk carrier', 'island reef', 'sailboat', 'other ship']
以上是本次比赛所使用的数据集yaml文件,文件里指明了:
- 训练图片位于
./data/images/train/路径;不必指明label存放的路径,程序会自行根据图片路径去寻找对应/path/of/data/路径下的labels。 - 验证集和测试集图片的路径;路径下可以不设图片,但路径应当存在,否则跑
train.py的时候会报错。可以修改train.py--train()函数第65行及相关部分,使train和test完全解耦避免该错误。当然也可以改test.py文件,时间有限,我没有去修改。 - NumberOfClasses,类别数目。有几类写几类即可,不用像YOLOv3一样在类别过少的时候手动增大预测类别数。特别的,当
nc = 1的时候,损失函数应当是有变化的,此处不予讨论。 - 各类类别名称,应当和
voc2yolo.py内的类别名称列表一致。
模型解读
训练的时候需要指定一个 --cfg 参数,也即训练使用的模型是什么样的。
yolov5 使用 yaml 格式文件存储和描述网络模型,非常简单易懂人性化。由于面对不同的任务和场景可能对模型进行一些自定义的修改,所以对检测模型的 yaml 格式表现做简单了解还是有必要的。首先给出一个yolov5网络整体图示如下。
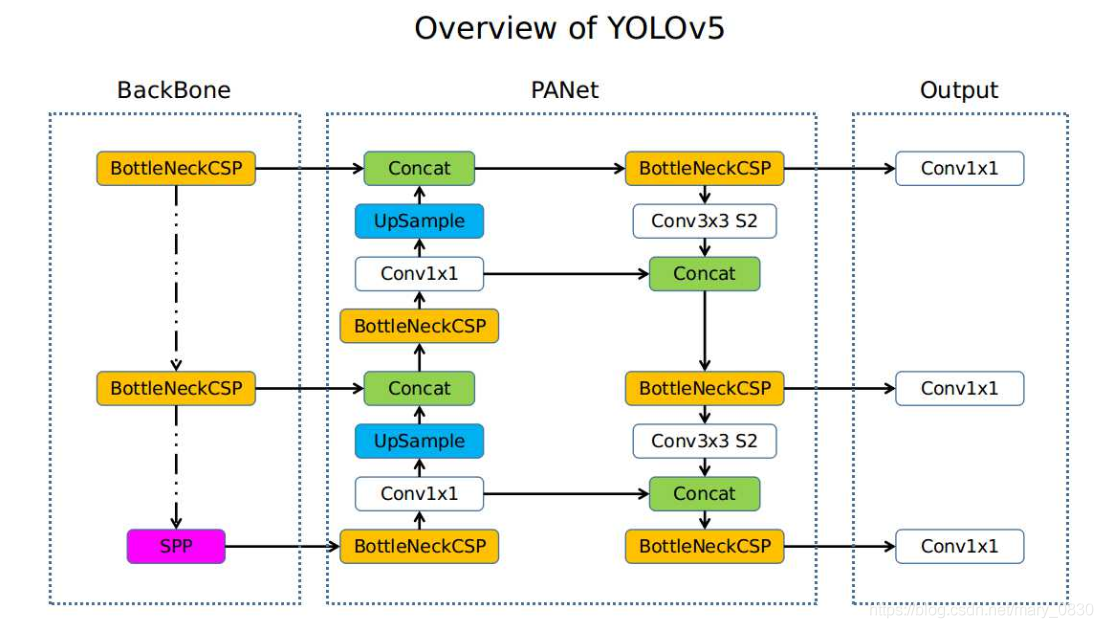
接下来是对应的以yolov5s小模型为例的yaml文件解析。
parameters
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
对于普通需求的网络scale变化,只改这一部分就够了。其中
nc是网络softmax层实际输出的类别数,有多少类别就填多少。depth_multiple是深度scale参数,按比例控制深度,也就是可堆叠层的堆叠数量。width_multiple是宽度scale参数,按比例控制宽度,也就是每层的的神经元数量。
anchors
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
跟检测层对应就行,不需要过多关注。u版v5在训练过程中会自动给出k-means得到的最佳anchors。
backbone
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
先看注释行 # [from, number, module, args],对应的就是下方每一行的四个组成单元:
from。来自哪儿,也即当前层输入来自哪一层。-1表示前一层,-2表示前两层,具体的数值则表示第几行,注意,虽然存在number参数用来表示某模块堆叠了多少层。事实上计算from及每行后面注释采用的层计数方式依然是第几行。number。该模块重复堆叠了多少层。一般的,具有一致输入输出特征维度的模块,往往具有大于一的number参数,也即往往会反复堆叠好多层。depth_multiple调节的主要部分就是这个数值。module。模块类型,根据./models/common.py中的定义解析。args。模块的具体参数,如第五层卷积Conv模块的[512, 3, 2],当width_multiple = 0.5时,表示“输入通道为128(根据上一层),输出通道为256,卷积核尺寸3 $\times$ 3,步长为2”的卷积模块。 这里需要格外注意一点,args 不需要指定输入通道数c_in,yolov5会自动将该参数解析为上一层的输出。解析文件在哪儿没找到。
backbone部分总共10层,其中第 0 层为 Focus 模块,至第 9 层 BottleneckCSP为止。
head
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
head 结构实际上包含了 neck 和 head 两部分,参数意义和 backbone 一样。自序数 0 起的第 10 层开始,至 23 层结束,序数第 24 层是检测层。
到这里整体的网络结构就出来了,很显然是个 “下采样 –> 上采样 –> 下采样” 的经典监测网络 N 型结构。其中的 下采样 由步长为 2 的卷积 Conv 实现, 上采样则是默认的 nn.Upsample 模块。
以YOLOv5s结构为例,且不计图像输入起始的 Focus 层(图像切片降低特征图长宽维度, 记为第 0 层),第一阶段下采样发生 backbone 部分,总共进行了四次,分别发生在 1, 3, 5, 7 层。第四次下采样结束,特征图尺寸跌至最小,为输入尺寸的 $\frac{1}{32}$ 。
位于 head 前半部分,实际上是 neck 部分的上采样总共发生了两次,分别在 11, 15 层。至序数第 17 层, neck 层结束, 特征图尺寸恢复到输入图像尺寸的 $\frac{1}{8}$ 。 18 层开始真 $\cdot$ head 部分,至 23 层结束。位于该部分的第二阶段下采样总共发生两次,分别在 18, 21 层。下采样结束后特征图尺寸又跌至输入图像尺寸的 $\frac{1}{32}$ 。
N 型结构中的 concat 特征融合和多尺度输出解析
注意几个 concat 层和 bounding boxes 回归计算输出层。YOLO系列常规尺寸都是三尺度输出,当然这可以自己改,后面会给出介绍。
第一次 concat 紧跟着第一次上采样而发生,位于序数 12 层。此时特征图尺寸为 $\frac{1}{16}$ 输入图像,于是寻找 backbone 部分有相同尺寸特征图的网络层位置,是最后一次下采样之前,第三次下采样之后。于是和第三次下采样后的第 6 层 BottleneckCSP 进行了 concat 操作。
<1> 关于 concat 输入层的选择问题需要注意,一是尽量保证 concat 操作的输入是信息丰富的特征图,于是选择 backbone 部分下采样后又进行了 BottleneckCSP 操作的特征图;二是 concat 之后应当紧跟着进行一些卷积这样的操作进行特征融合,于是另一个输入选择只经上采样输出的特征,而不是上采样后又进行的 BottleneckCSP 输出的特征,从而可以使用 BottleneckCSP 模块进行 concat 之后的特征融合。当然在上采样之后跟上几层卷积再 concat ,后面用于特征融合的 BottleneckCSP 不变也可以,但这样就徒增了计算量。
进行完第一次 concat + BottleneckCSP 的特征融合后,
第二次 concat 紧跟着第二次下采样发生,位于序数 16 层。此时特征图尺寸为 $\frac{1}{8}$ 输入图像,于是寻找 backbone 部分有相同尺寸特征图的网络层位置,是倒数第二次下采样之前,第二次下采样之后。于是和第二次下采样后的第 4 层 BottleneckCSP 进行了 concat 操作。其输入特征图依然遵守 <1> 所述准则。
注意到此时特征图达到了 backbone之后的最大尺寸,可以用来计算较大特征图下的用于较小目标检测的 bounding box 回归框了。于是位于序数 24 层的检测层 Detect 将序数 17 的 BottleneckCSP 作为输入之一。也可以继续上采样扩大特征图尺寸,但性价比不高。
第三次 concat 紧跟着第二阶段第一次下采样发生,位于序数 19 层。特征图尺寸变小为 $\frac{1}{16}$ 输入图像。由于上一阶段上采样阶段已经融合过 backbone 部分该尺寸特征图的信息了,则更好的选择是和上采样阶段的特征图做 concat。寻找上采样部分有相同特征图的网络层位置,是第一次上采样之后,第二次上采样之前。于是按照 <1> 中准则,分别选择当前(第二阶段第一次下采样)的输出和第二次上采样之前序数为 14 的 Conv 层输出作为输入,后跟一个 BottleneckCSP层进行特征融合。
此时特征图相比上一个输入到检测层特征图尺寸变小,可以用来计算中等特征图尺寸下的用于中等规模目标检测的 bbox 回归框。于是位于是位于序数 24 层的检测层 Detect 将序数 20 的 BottleneckCSP 作为输入之一。
第四次 concat 紧跟着第二阶段第二次下采样发生,位于序数 22 层.此时特征图尺寸继续变小到 backbone 部分下采样结束后的尺寸,$\frac{1}{32}$ 输入图像。该尺寸特征图也作为上采样阶段的输入特征图尺寸,从而上采样没有融合过 backbone 部分中该尺寸特征图的信息。寻找此前部分有相同尺寸特征图的最近网络层位置,是 backbone 最后一次下采样之后,第一次上采样之前。于是选择当前下采样层输出和第一次上采样的输入,也即第一次上采样之前序数为 10 的 Conv 层输出作为输入,后面还是跟一个 BottleneckCSP 进行特征融合。
此时特征图尺寸回落到最小,可以用来计算较小尺寸特征图下用于较大尺寸目标检测的 bbox 回归框。于是位于是位于序数 24 层的检测层 Detect 将序数 23 的 BottleneckCSP 作为输入之一。
添加自定义检测层
为了在单图像多目标检测任务中取得更好的效果,添加更多 anchors 不失为一个好方法,虽然提升也不怎么明显。原始的yolo设置时一个检测层给出三组不同的 anchors, 于是通过单纯向检测层中添加 anchors 是相对简单的。但没什么卵用。稍微有点儿卵用的方法是不止给每个检测层添加更多 anchors,同时通过添加更多检测层的方式增加 anchors 数量。
在已经了解了yolo检测网络 N 型结构组成的基础上,容易得出添加更多检测层的方法:在 backbone 允许的深度范围,继续叠加上采样和第二阶段下采样层;如果 backbone 的深度不允许,顺便增加 backbone 的深度。
这里展示一份比赛用的五个检测层、每层四个 anchors 的模型的 yaml 文件:
# parameters
nc: 6 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
# anchors
anchors:
- [9, 13, 15,9, 20,14, 21,35]
- [60,25, 48,67, 72,60, 61,131]
- [176,44, 114,121, 202,331, 381,92]
- [203,224, 224,108, 324,499, 442,160]
- [300,500, 412,277, 400,400, 500,200]
# - [10,13, 16,30, 33,23] # P3/8
# - [30,61, 62,45, 59,119] # P4/16
# - [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [512, 3, 2]], # 7-P5/32
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [512, 3, 2]], # 9-P6/64
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 11-P7/128
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 13
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 10], 1, Concat, [1]], # cat backbone P6/64
[-1, 3, BottleneckCSP, [512, False]], # 17
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P5/32
[-1, 3, BottleneckCSP, [512, False]], # 21
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4/16
[-1, 3, BottleneckCSP, [512, False]], # 25
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3/8
[-1, 3, BottleneckCSP, [256, False]], # 29 (P3/8-xsmall)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 26], 1, Concat, [1]], # cat head P4/16
[-1, 3, BottleneckCSP, [512, False]], # 32 (P4/16-small)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 22], 1, Concat, [1]], # cat head P5/32
[-1, 3, BottleneckCSP, [1024, False]], # 35 (P5/32-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P6/64
[-1, 3, BottleneckCSP, [1024, False]], # 38 (P6/64-large)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head before P6
[-1, 3, BottleneckCSP, [1024, False]], # 41 (P7/128-xlarge)
[[29, 32, 35, 38, 41], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6, P7)
]
可以看出,我们希望叠加更多上采样,但 backbone 深度不允许,于是顺带增加了两层 512 宽度的 backbone 下采样。而 backbone 结束后的特征图尺寸也从未增加时的 $\frac{1}{32}$ 继续跌落至 $\frac{1}{128}$ 输入图像。这就为 neck 和 head 部分的上采样和二次下采样创造了条件。后面 concat 和检测层 bbox 计算部分依照 N 型结构中的 concat 特征融合和多尺度输出解析 子节进行设置。
训练
训练没什么好讲的,只是参数的设置而已。yolov5的训练超参很多,此处择其要者做些介绍。
–weights
预训练权重路径。默认的是yolov5s.pt,如果不指定该参数的话会默认指向yolov5s.pt。于是如果是从头训练,不使用预训练模型的话,应当使之指空:
python train.py --weights '' --[other argvs ...]
注意到这个参数的名字是weights是复数形式。事实上,u版框架的确提供了 Ensemble learning 机制,但一般认为 Ensemble learning 是独立训练多个弱学习器,在 inference 阶段才组合成一个强学习器。训练的时候能不能指定多个 weights ,如果指定了会发生什么,都没有尝试,同时也不建议尝试。
–cfg
模型描述文件所在路径。一般是位于 ./models/ 路径下的诸 yaml 文件,或也可以自己写。模型文件的具体理解参照 模型解读 章节。
–data
数据描述文件所在路径。一般是位于 ./data/ 路径下的诸 yaml 文件。数据集描述文件的具体理解参照 数据集布置和yaml指向 子节。
–hyp
训练超参文件所在路径。一般是位于 ./data/ 路径下的 hyp.xxx.yaml文件。u 版 v5 提供了两个默认的超参描述文件,一个是用于从头开始训练的 hyp.stracth.yaml,一个是用于微调的 hyp.finetune.yaml 。超参文件里明确定义了不同阶段的学习率及其变化、动量及其变化、衰减及其变化, warmup 参数,分类及回归框损失参数,hsv 色域参数,图片旋转(degree)、缩放(scale)、错切(shear)、翻转(flip)、透视变换(perspective)、多图混合(mixup/mosaic)比例等训练诸参。
一般的,默认即可。如有需要,可自行调节如学习率、多图混合比例等部分参数。
–epochs
训练轮数。
–batch-size
每个批次(iter)加入的图像数量。实验表明,该值并不是越大越好,可能是受 train.py 文件第95行给定的 nominal batch size (nbs = 64) 的影响。实验表明,将这个值设置为 16 或 8 的效果相对更好。
–image-size
图像尺寸。很奇怪,明明代码里给出的 type 是 int 型,但 default 却是长度为 2 的列表; --help 给出的信息是 “ [train, test] image sizes “。
实测只填一个 int 型数字是可以的。同时由于依照 help 内容列表形式表示的意思是训练(前一个数)和测试(后一个数)时的输入图像尺寸,为保证测试效果达到最好,我们也建议其测试输入和训练保持一致,也即,填一个数。
比赛中将这个值设置为 512,发现和默认 640 尺寸的效果几乎没有差别。后面参加工训比赛,将这个值砍到 192,最后的精度差别也不大,反而速度获得了大幅提升。所以建议,填一个 512 就成了。
–noautoanchor
不自动更新 anchors ,不加该参数默认是自动更新的 。除非对自己设置的 anchors 有执念,不要加入该参数停掉自动更新,总之别管它。
–evolve
进化算法生成最合适的 hyp 超参数描述文件。加入这个参数会花费默认600 * epochs 轮迭代更新训练超参数。evolve 过程不算正式的训练,且非常费时间,且对最终效果的提升有限。如果时间不是十分充裕,不用管它。
–chche-images
将图像加入到缓存,以加快训练。加入缓存这个过程本身会花费不少时间,但对后面的训练加速确实有效,有点儿效果吧,当训练轮数非常多时,加入该参数能使总体时间减少。但是缓存空间在哪儿却不知道,反正不在内存,也就是说应当还是从磁盘中读取,只不过通过某种方式加速了这个读取过程。
–device
一个或用逗号隔开的多个阿拉伯数字,指定训练所使用的GPU卡号。或者填 cpu 指定使用cpu训练。
跟 CUDA_VISIBLE_DEVICES=[x,y,z,...] 效果一致。
–multi-scale
多尺度训练。加入该参数,训练加入的图像尺寸将在一定范围内(默认是 $\pm 50\%$ )随机浮动。
对最终效果有一定的提升,但训练开销陡增。有用,但性价比不算高。同时加入这个参数后要注意控制 image-size / batch-size参数,否则图像尺寸增大时会爆显存。
–single-cls
数据集内只有单个种类目标时使用。加入该参数,输出层激活函数和损失函数会发生变化,最直接的是,分类损失消失。
–adam
加入该参数,使用 adam 优化算法。无数论文和比赛都在吹 adam 算法多有效,然而我使用的时候,无论数据集和学习率等参数怎样设置,adam 都被 SGD 甩出两条街。不知道是不是我打开的方式不对。总之,不建议加入该参数。
–sync-bn
同步batch-norm,多卡 DDP mode 分布式训练时使用。DDP模式分布式训练的内容在后面,但,实测这个选项好像没什么用,或者有点儿用,用处不大。
others
其他的参数无关紧要,或非常紧要;不用动,或不要动。
多卡训练的正确打开方式 DDP
u版yolov5提供了两种多卡数据并行的方式:
- 数据并行(DP,DataParallel Mode), ( Not Recommended):
$ python train.py --[argvs] --device 0,1据说跟单卡训练差别不大,值得注意的是此时的
--batch-size参数,仍然是minibatch-size,是从默认的 64 的Total-batch-sizedivide 出来的。 - 分布式数据并行(DDP, DistributedDataParallel Mode),( Recommended):
$ python -m torch.distributed.launch --nproc_per_node 2 train.py --batch-size 64 --[argvs] --device 0,1这就有意思了,采用
pytorch原生的分布式训练方式,-nproc_per_mode参数代表训练使用的 GPU 个数,后面也可以使用--device参数指定具体编号 GPU。在此例中,使用编号为 0,1 的两块GPU进行分布式训练。
issue中提到,0号卡往往会承担更高的显存使用。那我要是不指定零号卡呢?没尝试过,我的机器只有两块卡。
此时的--batch-size成为了Total-batch-size,指定的该--batch-size会被平均 divide 到各个 GPU ,于是 issue 中要求其必为训练所使用 GPU 个数, 也即-nproc_per_node参数值的整数倍。结束